
Ein gutes integration testing example zeigt nicht nur, dass einzelne Funktionen sauber rechnen, sondern ob Daten, Schnittstellen und externe Dienste im Zusammenspiel wirklich funktionieren. Genau dort entstehen in Softwareprojekten die meisten Fehler: ein Request wird korrekt angenommen, aber nicht sauber gespeichert; eine Nachricht wird verschickt, aber der nachgelagerte Prozess reagiert falsch. In diesem Artikel zeige ich praxisnah, wie ich Integrationstests aufbaue, welche Beispiele im Alltag am meisten bringen und wo die Grenze zu Unit- und End-to-End-Tests liegt.
Die wichtigsten Punkte auf einen Blick
- Integrationstests prüfen das Zusammenspiel mehrerer Komponenten, nicht die Logik einer einzelnen Funktion.
- Am nützlichsten sind sie an Schnittstellen wie Datenbank, API, Message Queue oder Zahlungsdienst.
- Ein realistischer Testfall prüft mehr als den HTTP-Status, etwa Persistenz, Events und Folgeschritte.
- Zu viel Mocking macht Integrationstests schnell wertlos, weil dann genau die Integrationsschicht verschwindet.
- Saubere Testdaten und eine kontrollierte Umgebung sind wichtiger als möglichst viele Testfälle.
- Ich setze Integrationstests am liebsten dort ein, wo ein Fehler teuer wäre oder erst spät auffallen würde.
Was Integrationstests in der Praxis wirklich beweisen
Ich trenne Integrationstests bewusst von Unit-Tests: Ein Unit-Test prüft eine kleine, isolierte Einheit, ein Integrationstest prüft dagegen, ob mehrere Bausteine zusammen funktionieren. Das kann zum Beispiel die Verbindung zwischen Service-Schicht und Datenbank sein, die Verarbeitung eines API-Requests oder das Zusammenspiel mit einem externen Dienst. Entscheidend ist nicht, dass alles „echt“ im Sinne von Produktion ist, sondern dass die relevante Verbindung nicht mehr nur simuliert wird.
Ein Stub ist dabei ein einfacher Platzhalter, der definierte Antworten liefert, ohne eigene Logik zu testen. Ein Mock geht einen Schritt weiter: Er ersetzt ein Verhalten und kann zusätzlich prüfen, ob eine erwartete Nachricht oder ein Aufruf wirklich stattgefunden hat. Genau hier liegt eine typische Falle, denn wenn ich zu viel mocke, teste ich am Ende nur noch mein Testgerüst und nicht mehr die eigentliche Integration.
| Testtyp | Was er prüft | Stärke | Grenze |
|---|---|---|---|
| Unit-Test | Eine einzelne Funktion oder Klasse | Schnell und präzise | Sieht keine echten Schnittstellenprobleme |
| Integrationstest | Zusammenspiel mehrerer Komponenten | Findet Fehler an Übergängen | Langsamer und aufwendiger aufzusetzen |
| End-to-End-Test | Gesamten Nutzerfluss | Hohe Realitätsnähe | Teuer in Pflege und oft fragiler |
In einem Projekt möchte ich nicht raten, ob ein Fehler aus der Fachlogik, aus der Datenhaltung oder aus der Verbindung zwischen beiden kommt. Genau deshalb sind saubere Integrationstests so wertvoll, und im nächsten Abschnitt zeige ich das an einem konkreten Ablauf.
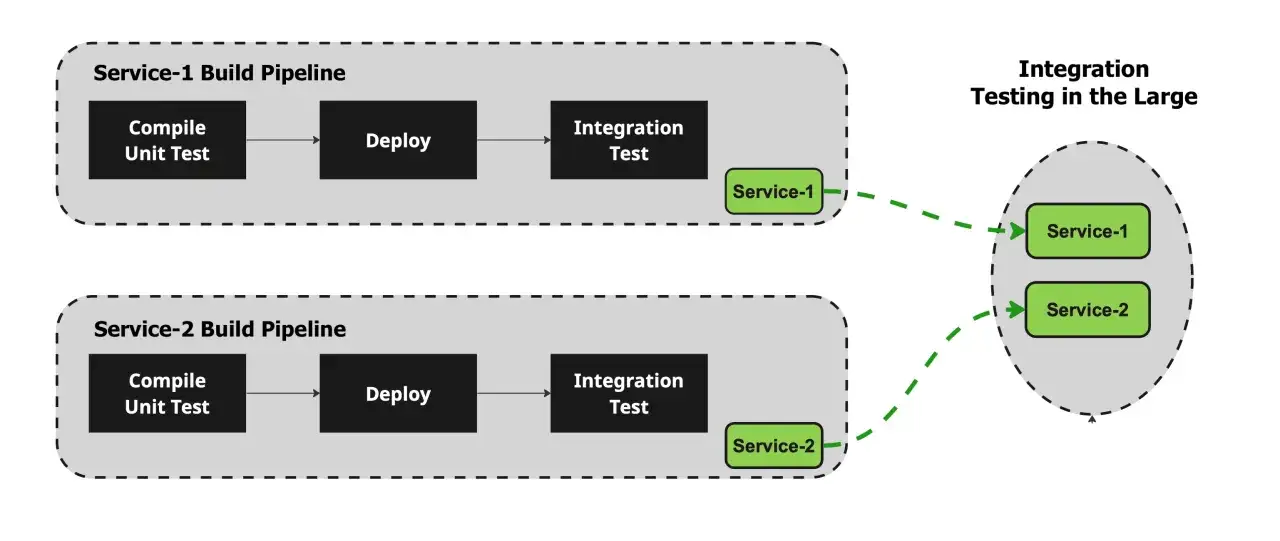
Ein realistisches Beispiel aus einem Bestellprozess
Das praktischste Beispiel ist für mich fast immer ein Checkout: Ein Kunde legt ein Produkt in den Warenkorb, bestätigt die Bestellung und löst damit mehrere Schritte aus. Die Anwendung schreibt die Bestellung in die Datenbank, prüft den Bestand, stößt im Idealfall eine Zahlungsprüfung an und erzeugt anschließend eine Bestätigungsmail oder ein Event für den Versand. Wenn an einer Stelle etwas schiefgeht, ist das für den Nutzer sofort spürbar.
So teste ich diesen Ablauf Schritt für Schritt:
- Ich starte mit einer sauberen Testdatenbank und lege einen bekannten Produktbestand an.
- Ich sende eine Bestellung über die API, so wie es auch ein Frontend oder ein externer Client tun würde.
- Ich prüfe, ob der Bestellstatus korrekt gespeichert wurde, zum Beispiel als „bezahlt“ oder „wartet auf Zahlung“.
- Ich kontrolliere, ob der Lagerbestand angepasst wurde und ob ein Bestellereignis ausgelöst wurde.
- Ich simuliere einen Fehlfall, etwa eine abgelehnte Zahlung, und prüfe, ob der Prozess sauber zurückrollt oder in einen definierten Zwischenstatus geht.
Der eigentliche Mehrwert liegt nicht in der Antwort „200 OK“, sondern in den Folgen: Wurde der Datensatz wirklich geschrieben, wurde die Nebenwirkung ausgelöst, und bleibt das System konsistent, wenn ein externer Schritt fehlschlägt? Genau diese Fragen trennen einen nützlichen Integrationstest von einer bloßen API-Abfrage. Damit ist der Ablauf sichtbar, aber noch nicht stabil, und deshalb kommt als Nächstes die Testumgebung ins Spiel.
So setze ich die Testumgebung sauber auf
Wenn Integrationstests unzuverlässig werden, liegt das sehr oft nicht an der Fachlogik, sondern an der Umgebung. Ich arbeite deshalb mit einer kontrollierten Testumgebung, in der Datenbank, Konfiguration und abhängige Dienste klar definiert sind. In modernen Projekten ist das oft ein Container-Setup, manchmal auch ein In-Memory-Dienst oder eine dedizierte Testinstanz, aber die Grundregel bleibt gleich: Die Umgebung muss reproduzierbar sein.
Für die Praxis hat sich für mich eine einfache Reihenfolge bewährt:
- Testdaten minimal halten, damit ein Fehler nicht hinter unnötigem Datenrauschen verschwindet.
- Externe Dienste bewusst trennen, wenn sie nicht der eigentliche Integrationspunkt sind.
- Deterministische Werte verwenden, etwa feste Zeitpunkte, IDs oder Zufallswerte mit Seed.
- Cleanup automatisieren, damit jeder Testlauf mit einem identischen Zustand beginnt.
- Wichtige Abhängigkeiten explizit konfigurieren, statt sie stillschweigend aus der Entwicklungsumgebung zu übernehmen.
Bei Drittanbieter-APIs prüfe ich zusätzlich oft, ob ein Contract-Testing-Ansatz sinnvoll ist. Dabei geht es darum, dass beide Seiten dieselben Erwartungen an Request und Response haben, ohne jeden externen Dienst im Vollbetrieb mitzuschleppen. Wenn der Aufbau stimmt, treten die eigentlichen Schwächen erst bei den typischen Fehlern zutage.
Die häufigsten Fehler, die Integrationstests schwach machen
Der häufigste Fehler ist aus meiner Sicht übermäßiges Mocking. Dann läuft der Test zwar grün, aber die eigentliche Verbindung zwischen Modulen wird gar nicht mehr geprüft. Das passiert vor allem dann, wenn Entwickler aus Angst vor langsamen Tests alles ersetzen, was nicht direkt im Code des eigenen Moduls liegt.
Ebenso problematisch sind instabile Testdaten. Wenn ein Test gestern noch bestanden hat und heute wegen eines globalen Datenzustands fehlschlägt, vertraut irgendwann niemand mehr auf das Ergebnis. Ich vermeide deshalb gemeinsame Datenbanken für parallele Läufe, unklare Seed-Daten und Tests, die von der Reihenfolge anderer Tests abhängen.
- Zu viele Behauptungen pro Test machen die Ursache eines Fehlers schwer erkennbar.
- Nur den Statuscode zu prüfen deckt keine Persistenz- oder Nebenwirkungsfehler ab.
- Zu breite Tests werden schnell kleine End-to-End-Suiten und sind dann schwer zu warten.
- Zeitabhängige Logik ohne Kontrolle führt zu Flakiness, also Tests, die zufällig scheitern.
- Unklare Testgrenzen sorgen dafür, dass niemand weiß, ob der Fehler im Code oder im Testaufbau liegt.
Ich teste deshalb lieber gezielt einen klaren Integrationspunkt sauber als fünf Prozesse gleichzeitig halbherzig. Genau an dieser Stelle hilft der Vergleich mit anderen Testarten, damit die Grenzen nicht verschwimmen.
Wann ich Integrationstests mit anderen Testarten kombiniere
Integrationstests ersetzen keine Unit-Tests, und sie ersetzen auch keine End-to-End-Tests. Ich sehe sie als Mittelweg: Unit-Tests geben mir Tempo und Präzision, Integrationstests geben mir Vertrauen an den Schnittstellen, und End-to-End-Tests sichern nur die wichtigsten Nutzerwege ab. Wer alles über einen einzigen Testtyp abdecken will, zahlt am Ende fast immer mit Wartungskosten oder mit Lücken im Schutz.
| Frage | Unit-Test | Integrationstest | End-to-End-Test |
|---|---|---|---|
| Prüft er Fachlogik isoliert? | Ja | Teilweise | Nein |
| Prüft er Schnittstellen und Datenfluss? | Kaum | Ja | Ja, aber breiter und teurer |
| Ist er schnell genug für häufige Läufe? | Ja | Meist mittel | Eher nein |
| Ist er gut für kritische Geschäftsprozesse? | Nur eingeschränkt | Sehr gut | Gut, aber mit höherem Pflegeaufwand |
Für die Praxis heißt das für mich: Die Mehrheit der Logik gehört in schnelle Unit-Tests, die risikoreichen Übergänge in Integrationstests und die wichtigsten Nutzerpfade in eine kleine Zahl stabiler End-to-End-Tests. So bleibt die Suite schnell genug für den Alltag und trotzdem aussagekräftig. Am Ende geht es nicht um möglichst viele Tests, sondern um einen verlässlichen Mix mit klarer Aufgabe.
Worauf ich für einen belastbaren Testmix achte
Wenn ich ein Testsystem langfristig brauchbar halten will, achte ich vor allem auf Klarheit. Jeder Integrationstest braucht einen klaren Zweck: eine Datenbanktransaktion, einen API-Call, ein Messaging-Event oder eine andere konkrete Verbindung. Sobald ein Test mehrere Zwecke gleichzeitig verfolgt, wird er schwer lesbar und im Fehlerfall langsam diagnostizierbar.
Ich halte außerdem den schnellen Kern klein und stabil. Ein paar wenige, gut gewählte Integrationstests bringen mehr als eine große Sammlung unklarer Fälle, die nur im CI-Job gelegentlich Zeit kosten. In der Praxis ist es oft besser, kritische Pfade eng zu überwachen und Randfälle gezielt dort zu testen, wo sie die Ursache am besten sichtbar machen. Genau das ist für mich der Unterschied zwischen einem Testbestand, der nur existiert, und einem Testbestand, auf den man sich wirklich verlassen kann.
Wer mit einem ersten konkreten Beispiel starten will, sollte nicht versuchen, das ganze System auf einmal abzusichern. Ich würde immer mit dem einen Fluss beginnen, bei dem ein Fehler am teuersten wäre, etwa Bestellung, Login, Zahlungsabwicklung oder Datenimport. Sobald dieser Pfad sauber getestet ist, lässt sich das Konzept kontrolliert erweitern, ohne dass die Testsuite unnötig schwerfällig wird.