
Der Eclipse Dataspace Connector ist ein Rahmenwerk für den souveränen Datenaustausch zwischen Organisationen, nicht einfach nur ein weiteres Integrationswerkzeug. Für Datenanalyse und Datenbanken ist er vor allem dann interessant, wenn Daten kontrolliert freigegeben, vertraglich geregelt und dennoch in bestehende Analyseketten eingebunden werden sollen. Ich ordne ihn deshalb eher als Steuerungs- und Vermittlungsschicht ein als als Speicher oder BI-Komponente.
Die zentrale Idee ist kontrollierter Datenaustausch statt blindem Kopieren
- Der Connector vermittelt zwischen Datenanbieter und Datennutzer, inklusive Katalog, Vertragsverhandlung und Transfer.
- Er ersetzt weder Datenbank noch Data Warehouse, sondern setzt davor an und regelt den Zugriff.
- Für Analysen ist er stark, wenn Berechtigungen, Identität und Nutzungsregeln zwischen Unternehmen sauber durchgesetzt werden müssen.
- Besonders sinnvoll ist er in föderierten Datenräumen, etwa in Industrie-, Lieferketten- oder Forschungskontexten.
- Wer nur intern Daten bewegt, kommt oft mit einfacheren Mitteln schneller und günstiger ans Ziel.
Was der Connector in einer Datenraum-Architektur leistet
Ich sehe den Connector vor allem als technische Antwort auf eine organisatorische Frage: Wer darf welche Daten unter welchen Bedingungen nutzen, ohne dass die Datenhoheit verloren geht? Das Framework bringt genau dafür die Bausteine mit, die in Datenräumen fehlen würden, wenn man nur mit klassischen APIs oder Dateitransfers arbeitet: Datensuche, Austausch, Nutzungsregeln, Überwachung und Protokollierung.
- Datenzugang wird nicht pauschal geöffnet, sondern gezielt über Angebote und Freigaben organisiert.
- Nutzungsregeln werden technisch durchgesetzt, statt nur in Verträgen zu stehen, die niemand im Alltag prüft.
- Identität sorgt dafür, dass ein Partner nicht nur eine technische Verbindung hat, sondern auch verlässlich authentifiziert ist.
- Monitoring und Audit machen nachvollziehbar, wer was wann angefordert oder übertragen hat.
- Erweiterbarkeit ist eingeplant, damit sich bestehende IT-Landschaften und Transfertechnologien anbinden lassen.
Wichtig ist: Der Connector verwaltet den Zugang, nicht den fachlichen Wert der Daten selbst. Wenn die Semantik eines Datensatzes unklar ist oder die Geschäftsverantwortung fehlt, hilft auch die beste technische Hülle nicht weiter. Sobald das klar ist, wird verständlich, warum die technische Abfolge so stark auf Metadaten, Identität und Policies setzt.
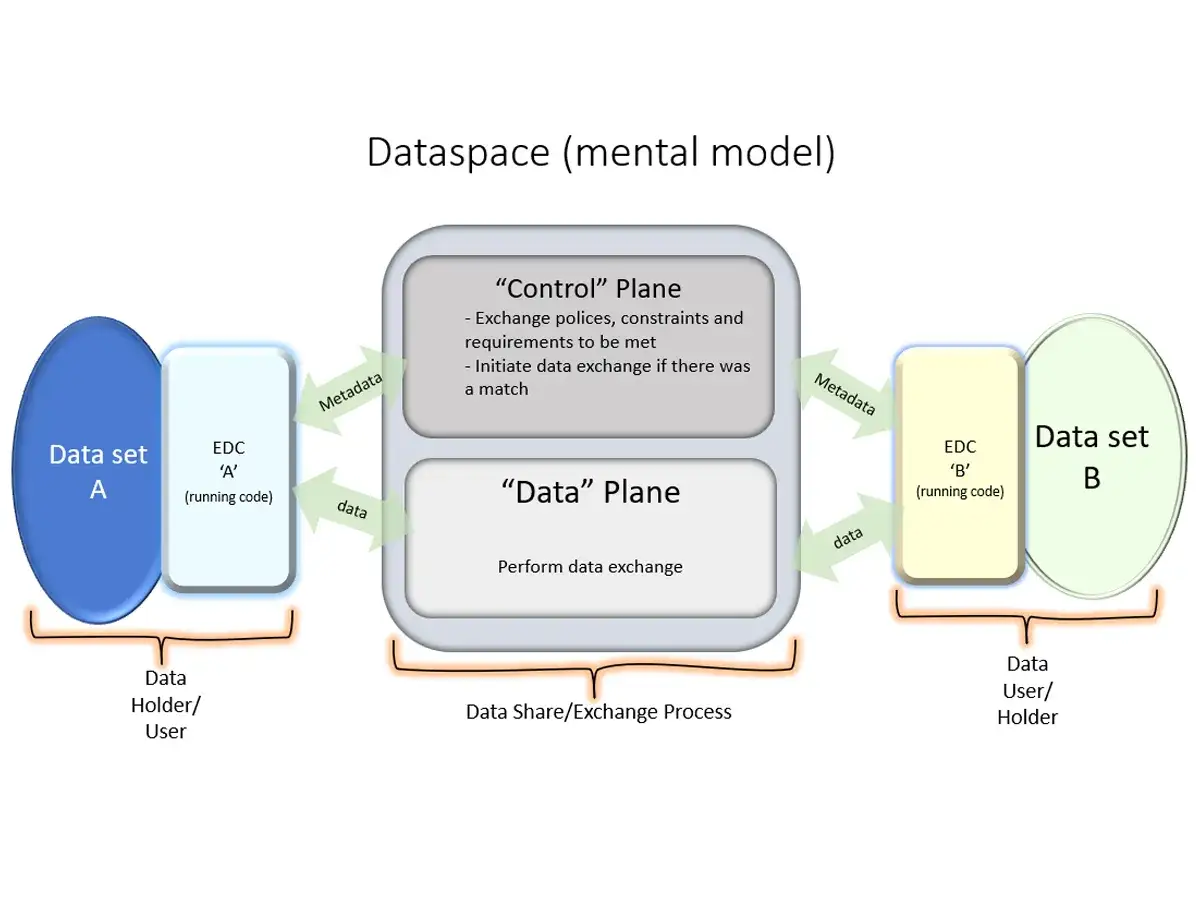
Wie die Architektur in der Praxis funktioniert
Die Architektur trennt bewusst zwischen Control Plane und Data Plane. Die Control Plane ist die Verwaltungs- und Entscheidungsebene: Hier werden Kataloge abgefragt, Verträge verhandelt und Transfers angestoßen. Die Data Plane ist die Transportebene: Sie übernimmt den eigentlichen Datenfluss über die passende technische Strecke, etwa per REST, Dateiübertragung oder Streaming.
- Catalog Request - Der Datennutzer fragt verfügbare Angebote ab und sieht, welche Datensätze überhaupt existieren.
- Contract negotiation - Anbieter und Nutzer einigen sich auf Nutzungsbedingungen, etwa auf Zweckbindung, Laufzeit oder Zugriffsbeschränkungen.
- Transfer process - Nach dem Vertrag werden die technischen Zugangsdaten für die Übertragung bereitgestellt.
- Data Plane - Die eigentliche Übertragung läuft über die dafür passende Technik, nicht zwingend über dieselbe Schnittstelle wie die Verhandlung.
Der praktische Vorteil liegt genau in dieser Trennung: Ein Partner kann Daten in einer API bereitstellen, ein anderer per Push in einen Datenspeicher liefern und ein dritter über einen Streaming-Kanal anbinden, ohne dass die Governance jedes Mal neu erfunden werden muss. Wer diesen Ablauf verstanden hat, sieht sofort, warum der Connector keine Datenbank ersetzt, aber sehr wohl den Datenzugriff kontrolliert.
Warum er für Datenanalyse und Datenbanken so interessant ist
Bei Analyseprojekten trenne ich drei Ebenen: Speicherung, Auswertung und Governance. Genau dort sitzt der Connector als zusätzliche Schicht, die festlegt, ob und wie Daten zwischen Organisationen wandern dürfen. Das ist der Punkt, an dem er für Datenanalyse und Datenbanken spannend wird.
| Baustein | Hauptaufgabe | Stark bei | Grenze |
|---|---|---|---|
| Datenbank | Daten speichern, konsistent halten und schnell bereitstellen | Operative Prozesse, transaktionale Workloads, saubere Datenhaltung | Regelt keine externen Datenverträge oder Partnerrechte |
| Data Warehouse / Lakehouse | Daten modellieren, aggregieren und für BI oder KI auswerten | Reporting, Trendanalysen, Machine-Learning-Workloads | Ist nicht automatisch ein souveränes Zugriffsmodell für mehrere Organisationen |
| Connector | Zugriffe, Bedingungen und Transfers zwischen Organisationen vermitteln | Datenräume, Partnerschaften, kontrollierte Freigabe, Auditierbarkeit | Berechnet keine Kennzahlen und ersetzt kein Analysewerkzeug |
Gerade bei Lieferketten-, Qualitäts- oder Produktionsdaten ist das ein großer Unterschied. Oft sollen Daten nicht zentral „abgegeben“ werden, sondern bleiben nahe an der Quelle und werden nur unter bestimmten Bedingungen nutzbar gemacht. Das ist kein technisches Detail, sondern die eigentliche Wertschöpfung im Datenraum: Analyse ja, aber mit klarer Kontrolle über Herkunft, Nutzung und Weitergabe. Von dort ist der Schritt zur konkreten Anbindung bestehender Systeme nicht mehr weit.
So binde ich bestehende Systeme sinnvoll an
Wenn ich ein Pilotprojekt plane, denke ich nicht zuerst an den Connector selbst, sondern an das Datenprodukt dahinter. Die Architektur muss zur Art der Daten passen: relationale Stammdaten, Ereignisströme, Dateien oder API-Antworten. Genau daraus ergeben sich vier typische Integrationsmuster.
| Muster | Wann es passt | Worauf ich achte |
|---|---|---|
| Direkter API-Zugriff | Wenn aktuelle Daten ohne große Kopien genutzt werden sollen | Rate Limits, Last auf dem Quellsystem, saubere Authentifizierung |
| Export in Staging oder Lakehouse | Wenn große Datenmengen analysiert oder historisiert werden sollen | Aktualisierungslogik, Datenqualität, Versionierung |
| Push an einen Datensink | Wenn der Anbieter Daten aktiv an den Verbraucher liefert | Zielsystem, Zugriffsrechte, technische Übergabeparameter |
| Streaming | Wenn Ereignisse oder Telemetrie laufend fließen sollen | Stabilität, Pufferung, Beobachtbarkeit und Fehlerbehandlung |
Bei relationalen Systemen würde ich den EDC in der Regel vor eine freigegebene Schnittstelle setzen, nicht direkt vor Tabellen und Views. Das hält das Betriebsrisiko kleiner und verhindert, dass analytische Zugriffe das operative System unnötig belasten. Bei solchen Integrationen hilft auch der modulare Aufbau des Projekts, weil sich Datenbank- und Transportkomponenten gezielt erweitern lassen, statt alles in einen Monolithen zu pressen. In der Praxis ist das oft auch der Punkt, an dem sich sauber zeigt, ob ein Projekt wirklich datenraumfähig ist oder nur eine zusätzliche API-Schicht bekommen hat.
Typische Fehler und Grenzen in frühen Projekten
Die meisten Probleme entstehen nicht am Code, sondern an falschen Erwartungen. Der Connector löst weder schlechte Datenqualität noch unklare Verantwortlichkeiten. Wenn Semantik, Zugriff und Lebenszyklus der Daten nicht sauber beschrieben sind, wird selbst ein technisch korrekter Transfer schwer wartbar.
- Als Ersatz für Datenintegration missverstanden - Ein Connector organisiert den Zugriff, aber er modelliert die Fachwelt nicht automatisch richtig.
- Policies zu spät definiert - Nutzungsregeln sollten vor dem ersten produktiven Transfer feststehen, nicht erst danach.
- Metadaten unterschätzt - Ohne klare Beschreibung von Inhalt, Struktur und Zweck bleibt der Datensatz schwer nutzbar.
- Zu nah an der operativen Datenbank - Wer direkt auf Produktivtabellen zugreift, riskiert Performance- und Governance-Probleme.
- Audit und Observability vergessen - Ohne Protokolle lässt sich später kaum nachweisen, was tatsächlich passiert ist.
Mein pragmatischer Maßstab ist einfach: Wenn ich Daten ohne lange Erklärungen sicher freigeben kann, ist die Architektur auf einem guten Weg. Wenn jedes Partnergespräch neue Sonderregeln erzeugt, fehlt meist noch die fachliche und technische Vorarbeit. Das ist die natürliche Grenze zwischen einem belastbaren Datenraum und einem bloßen Integrationsprojekt.
Wann sich der Einsatz in Deutschland besonders lohnt
In Deutschland spielt dieser Ansatz vor allem dort seine Stärken aus, wo Industriepartner, Forschungseinrichtungen oder Verbünde nicht einfach Dateien austauschen, sondern belastbare Regeln brauchen. Das sieht man besonders in Lieferketten-, Produkt- und Qualitätsdaten, aber auch in Forschungskooperationen, in denen Zugriffsrechte, Herkunft und Nachvollziehbarkeit wichtig sind.
- Mehrere Organisationen teilen ein gemeinsames Datenziel - etwa bei Produktions-, Logistik- oder Qualitätskennzahlen.
- Es gibt klare Verträge oder regulatorische Grenzen - dann ist technische Durchsetzung wichtiger als bloße Absprache.
- Die Daten sollen nicht zentral abgegeben werden - ein föderierter Ansatz schont die Datenhoheit der Beteiligten.
- Analysen sollen näher an der Quelle möglich bleiben - das reduziert unnötige Kopien und hält sensible Systeme unter Kontrolle.
Für rein interne BI-Landschaften ist der Aufwand oft zu hoch; dort sind klassische Replikation, ETL oder ein Warehouse schneller und günstiger. Sobald jedoch externe Partner, Nachweispflichten oder ein souveränes Datenmodell ins Spiel kommen, kippt die Rechnung zugunsten eines Datenraum-Ansatzes. Genau an dieser Stelle wird der Connector für deutsche Industrie- und Innovationsnetzwerke wirklich relevant.
Worauf ich vor dem produktiven Einsatz noch prüfen würde
Vor einem produktiven Start würde ich fünf Fragen konsequent abhaken: Wer besitzt die Daten, wer darf sie nutzen, wie lange gelten die Rechte, wie wird der Zugriff protokolliert und was passiert bei Widerruf? Diese Fragen sind banal, aber sie entscheiden darüber, ob das System später tragfähig bleibt.
- Ist das Datenprodukt fachlich klar beschrieben, inklusive Schema und Semantik?
- Sind Rollen für Anbieter, Konsument und Betreiber sauber getrennt?
- Gibt es ein Monitoring für Transfer, Fehler und Vertragsstatus?
- Ist das Quellsystem vor Lastspitzen geschützt?
- Lässt sich die Governance auch dann noch erklären, wenn mehrere Partner beteiligt sind?
Wenn diese Punkte stehen, wird aus dem Connector keine zusätzliche Komplexitätsschicht, sondern eine kontrollierte Infrastruktur für souveränen Datenaustausch. Genau dann lohnt er sich auch für Analyse- und Datenbanklandschaften wirklich.