
Apache Spark ist die Werkbank für große Datenmengen: eine verteilte Analyse-Engine, mit der sich Batch-Jobs, Streaming-Daten, SQL-Abfragen und Machine-Learning-Schritte in einer gemeinsamen Umgebung verarbeiten lassen. Der Kern hinter what is spark ist schnell erklärt, aber die praktische Bedeutung geht weiter: Wer Daten aus verschiedenen Quellen zusammenführt, bereinigt und für Analyse oder Modelle aufbereitet, trifft mit Spark oft genau die richtige Schicht im Stack. Für Datenanalyse und Datenbanken ist das relevant, weil Spark klassische Systeme nicht ersetzt, sondern dort stark wird, wo Volumen, Geschwindigkeit und Parallelität zusammenkommen.
Das Wichtigste in Kürze
- Apache Spark ist keine klassische Datenbank, sondern eine verteilte Analyse- und Rechenengine.
- Stark ist Spark bei Batch-Verarbeitung, Streaming, SQL und Datenaufbereitung auf großen Datenmengen.
- DataFrames und Spark SQL bilden die zentrale Arbeitsebene für strukturierte Daten.
- Für neue Streaming-Projekte ist Structured Streaming die richtige Wahl, nicht die alte Spark-Streaming-API.
- Im Vergleich zu Datenbanken gewinnt Spark, wenn Parallelität und Datenvolumen dominieren, nicht bei kleinen Transaktionslasten.
- Die größten Erfolgsfaktoren sind saubere Partitionierung, passendes Speicherbudget und ein gutes Datenmodell.
Was Apache Spark eigentlich ist
Ich würde Spark am saubersten als einheitliche Analyse- und Verarbeitungsschicht beschreiben. Die Engine liest Daten aus Dateien, Tabellen oder Streams ein, führt Transformationen verteilt aus und schreibt das Ergebnis wieder zurück. Sie läuft auf einem einzelnen Rechner genauso wie auf einem Cluster, skaliert also mit dem Problem statt mit einer festen Infrastrukturidee.
Der praktische Wert liegt darin, dass Spark mehrere Analysewelten unter einem Dach zusammenführt:
- Spark SQL für strukturierte Daten und SQL-nahe Abfragen.
- DataFrames als tabellarische Arbeitsform mit Optimierungen unter der Haube.
- Structured Streaming für kontinuierlich eintreffende Daten.
- MLlib für Maschinenlernen direkt auf denselben Datenpipelines.
Gerade DataFrames sind wichtig für das Verständnis: Sie verhalten sich konzeptionell wie Tabellen aus einer relationalen Datenbank, bringen aber die Verteilungs- und Optimierungslogik von Spark mit. Genau deshalb ist Spark für Datenanalyse so interessant. Man denkt in Tabellen, aber arbeitet in einer Engine, die groß skalieren kann. Wie diese Architektur intern arbeitet, sieht man erst beim Blick auf die Verarbeitungsschichten.
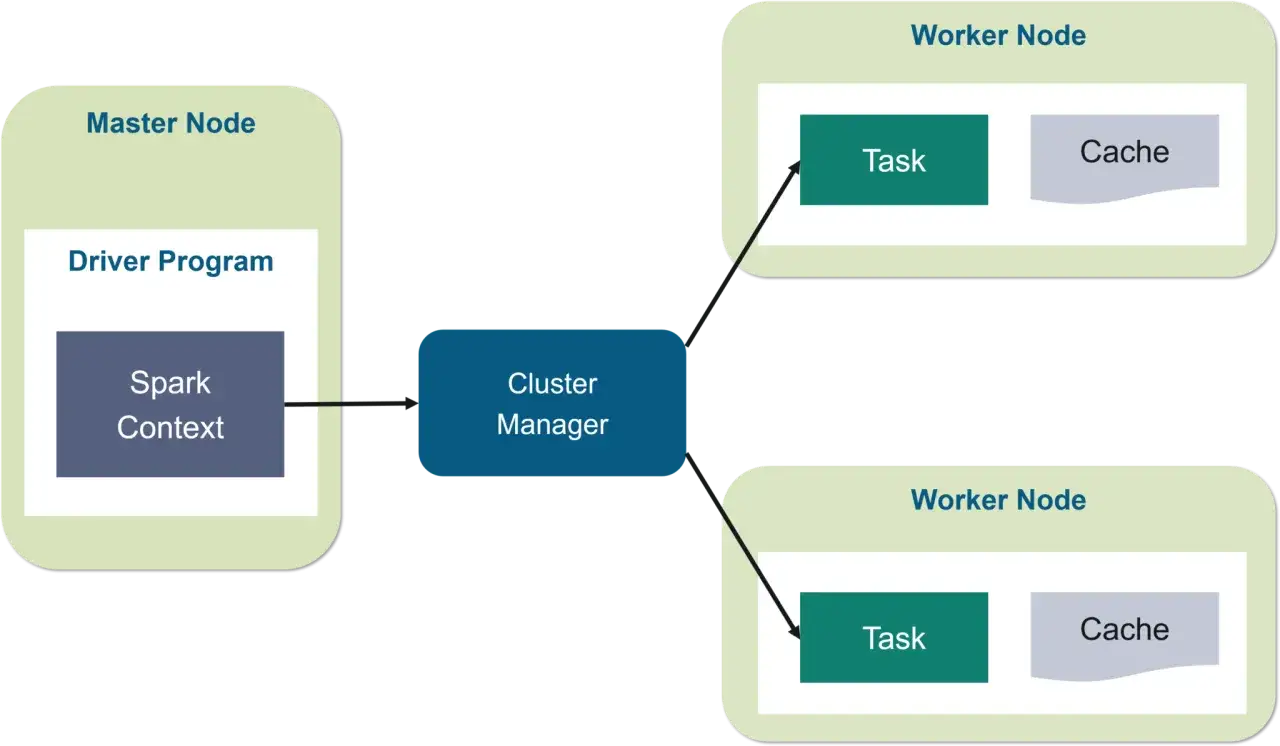
Wie Spark Daten verteilt verarbeitet
Der Kern von Spark ist die Arbeitsteilung. Ein Driver plant den Ablauf, verteilt Aufgaben und sammelt Ergebnisse ein. Die Executors rechnen auf den Arbeitern des Clusters die einzelnen Teilmengen ab. Daten werden in Partitionen zerlegt, damit mehrere Knoten parallel arbeiten können. Für große Analysen ist genau das der Unterschied zwischen „läuft irgendwie“ und „läuft beherrschbar“.
Besonders wichtig ist der DAG, also ein gerichteter azyklischer Graph. Dahinter steckt der Ausführungsplan, den Spark aus deinen Transformationen baut. Das System kann dadurch Schritte bündeln, Reihenfolgen optimieren und Fehler im Verteilungsprozess besser abfangen. Für mich ist das einer der Gründe, warum Spark in der Praxis robuster wirkt als viele selbst gebaute Batch-Pipelines.
Ein paar Begriffe sollte man sauber auseinanderhalten:
- Partitionierung bedeutet, dass große Daten in parallel verarbeitbare Blöcke geteilt werden.
- Shuffle ist der teure Datentausch zwischen Knoten, etwa bei Joins oder Aggregationen.
- Caching hält häufig genutzte Daten im Speicher, damit sie nicht erneut gelesen werden müssen.
- Broadcast Join verteilt eine kleine Tabelle an alle Worker, statt die große Tabelle unnötig zu bewegen.
Genau an diesen Punkten entscheidet sich oft die Performance. Wer Spark nur als „schnelles SQL“ versteht, übersieht den eigentlichen Hebel: Daten so zu schneiden und zu kombinieren, dass die verteilte Ausführung effizient bleibt. Daraus ergeben sich die typischen Einsatzfelder in Analyse und Streaming.
Wofür Spark in der Datenanalyse besonders stark ist
Für Datenanalyse ist Spark dann stark, wenn nicht nur ein einzelner Report erzeugt werden soll, sondern ganze Datenflüsse durch verschiedene Schritte laufen. Ich denke dabei an Rohdaten importieren, bereinigen, anreichern, aggregieren und erst danach für BI, Modelle oder operative Systeme bereitstellen.
ETL und Datenaufbereitung
ETL bedeutet, Daten zu extrahieren, zu transformieren und zu laden. Spark spielt hier seine Stärken aus, wenn Daten aus vielen Quellen zusammenkommen, etwa Logdateien, CSV-Exports, Datenbankauszüge und Objekt-Speicher. Die Engine kann diese Daten im gleichen Programm lesbar machen, vereinheitlichen und in ein analytisch brauchbares Format bringen. Das ist besonders nützlich, wenn Datenqualität nicht perfekt ist und ich Regeln, Typkonvertierungen und Dublettenbereinigung zentral abbilden will.
Streaming mit Structured Streaming
Für Live-Daten ist Structured Streaming die sinnvolle aktuelle Option. Spark behandelt den Datenstrom dabei wie eine fortlaufend wachsende Tabelle und rechnet die Ergebnisse inkrementell nach. Das ist ein gutes Modell für Klickdaten, Sensorwerte, Event-Logs oder Fraud-Signale. Wichtig ist: Die ältere Spark-Streaming-API gilt heute als Legacy, für neue Projekte würde ich sie nicht mehr wählen.
Machine Learning und Feature Engineering
Bevor ein Modell trainiert wird, müssen Merkmale erzeugt, skaliert und zusammengeführt werden. Spark hilft genau an dieser Stelle, weil dieselbe Engine große Feature-Pipelines und verteilte Vorverarbeitung tragen kann. Das spart Brüche zwischen Analyse- und ML-Stack. MLlib ist kein Ersatz für jedes spezialisierte ML-Framework, aber für klassische Pipeline-Schritte auf großen Datenmengen ist sie pragmatisch und solide.
Lesen Sie auch: Visual Studio SQL - Datenbankprojekte meistern & Fehler vermeiden
SQL auf großen Rohdatenbeständen
Viele Teams wollen gar nicht zuerst programmieren, sondern fragen Daten ab. Spark SQL macht das möglich, ohne die Programmierbarkeit der Engine aufzugeben. Man kann SQL mit DataFrame-Operationen mischen und strukturiert auf Rohdaten arbeiten, die zu groß für den lokalen Rechner oder zu unhandlich für eine einzelne relationale Datenbank sind. Gerade in Data-Lake-Architekturen ist das ein sauberer Weg, um Rohdaten analytisch nutzbar zu machen.Damit stellt sich die nächste Frage fast automatisch: Wann ist Spark besser als eine Datenbank, und wann nicht? Genau dort trennt sich der Hype von der Architekturentscheidung.
Spark, Datenbank und Data Warehouse im direkten Vergleich
Ich trenne diese Systeme bewusst nach Aufgabe, nicht nach Markenname. Spark ist für verteilte Verarbeitung und Analyse gebaut. Eine relationale Datenbank ist für Transaktionen, Konsistenz und schnelle Einzelzugriffe stark. Ein Data Warehouse liegt dazwischen, weil es analytische Abfragen auf kuratierten Daten optimiert.| Kriterium | Spark | Klassische relationale Datenbank | Data Warehouse |
|---|---|---|---|
| Hauptzweck | Verteilte Verarbeitung, Analyse, ETL, Streaming | Operative Transaktionen und strukturierte Einzelzugriffe | Analytische Abfragen und Berichte auf bereinigten Daten |
| Typische Datenmenge | Große Datenmengen bis in den Terabyte- und Petabyte-Bereich | Kleine bis mittlere bis größere operative Datenbestände | Große historische Datenbestände für Auswertungen |
| Stärken | Parallelität, flexible Pipelines, Batch und Streaming in einer Engine | ACID-Transaktionen, niedrige Latenz, saubere Integrität | SQL-Performance, BI, Governance, kuratierte Datenmodelle |
| Schwächen | Hoher Tuning-Aufwand bei schlechten Datenmustern, Overhead bei kleinen Jobs | Begrenzt bei sehr großen verteilten Transformationen | Weniger flexibel für rohe, komplexe Transformationsketten |
| Rolle im Stack | Verarbeitungs- und Analyseebene | System of Record für operative Prozesse | Analytische Reporting- und Aggregationsschicht |
Die eigentliche Erkenntnis ist simpel: Spark und Datenbank konkurrieren nicht eins zu eins. Häufig ergänzen sie sich. Die Datenbank sammelt und sichert operative Daten, Spark bereitet sie auf, verknüpft sie mit weiteren Quellen und macht daraus belastbare Analysen. Diese Arbeitsteilung funktioniert aber nur, wenn man die Grenzen sauber respektiert.
Wo Spark glänzt und wo ich bremsen würde
Spark ist mächtig, aber nicht magisch. Die häufigsten Probleme entstehen nicht in der API, sondern bei den Erwartungen. Wer Spark wie ein bequemes SQL-Frontend behandelt, wundert sich schnell über Speicherverbrauch, Shuffle-Kosten oder lange Laufzeiten. Aus meiner Sicht sind das die typischen Stolperstellen:
- Zu kleine Jobs: Wenn die Daten problemlos in eine einzelne Datenbank oder sogar in einen lokalen Prozess passen, ist Spark oft unnötig schwer.
- Viele kleine Updates: Für OLTP-artige Workloads mit ständigem Schreiben und Lesen ist eine relationale Datenbank meist die bessere Wahl.
- Unkontrollierte Joins: Große Joins ohne gutes Partitioning erzeugen teure Shuffles und drücken die Performance massiv.
- Datenskew: Wenn einzelne Partitionen viel größer sind als andere, wartet der ganze Job auf die langsamen Ausreißer.
- Streaming ohne Checkpointing: Wer Zustände nicht sauber absichert, macht sich fehlertolerante Verarbeitung unnötig schwer.
Ein weiterer Punkt ist Speicher und Infrastruktur. Spark profitiert stark vom Arbeitsspeicher, aber genau deshalb muss man ihn bewusst einsetzen. Ich würde ein Projekt immer zuerst auf Datenform, Zugriffsmuster und Wiederverwendung prüfen. Wenn die Analyse nur einmal läuft und kaum Parallelität braucht, ist Spark oft Overkill. Wenn derselbe Transformationspfad täglich über viele Datenquellen läuft, sieht die Rechnung ganz anders aus. Wer diese Grenzen kennt, kann Spark wesentlich sauberer einsetzen.
So setze ich Spark in Projekten sinnvoll ein
In der Praxis hilft mir ein einfacher Ablauf, um Spark nicht unnötig kompliziert zu machen. Die Reihenfolge ist wichtiger, als viele Teams denken: Erst Datenstruktur und Zielbild klären, dann rechnen. Nicht umgekehrt.
- Das Datenmodell vor dem Cluster denken: Ich definiere, welche Spalten wirklich gebraucht werden, welche Schlüssel stabil sind und wo Aggregationen stattfinden sollen.
- Saubere Formate wählen: Für analytische Workloads sind spaltenbasierte Formate wie Parquet oder ORC oft deutlich effizienter als rohe Textdateien.
- Mit DataFrames oder SQL arbeiten: Das hält den Code lesbar und gibt Spark die Chance, intern zu optimieren.
- Caching nur gezielt einsetzen: Ich speichere nur Daten zwischen, die wirklich mehrfach gelesen werden.
- Streams mit Checkpoints absichern: Bei kontinuierlichen Pipelines brauche ich einen reproduzierbaren Zustand, sonst wird Fehlerbehandlung schnell teuer.
- Schwere und leichte Tabellen bewusst trennen: Kleine Referenzdaten lassen sich oft als Broadcast Join verteilen, statt alles teuer durch den Cluster zu schieben.
Ein guter Praxistest lautet für mich immer: Würde ich denselben Schritt auch sauber erklären können, wenn ich die Implementierung einem Kollegen in drei Sätzen beschreiben müsste? Wenn die Antwort nein ist, steckt meist noch unnötige Komplexität im Design. Genau deshalb lohnt sich bei Spark nicht nur technisches Wissen, sondern auch architektonische Disziplin. Am Ende führt das zu einer einfachen Entscheidungshilfe.
Wann ich Spark einsetze und wann ich bei der Datenbank bleibe
Ich setze Spark ein, wenn ich große Datenmengen parallel verarbeiten muss, wenn Batch und Streaming zusammenkommen oder wenn SQL, Python und verteilte Ausführung in derselben Pipeline arbeiten sollen. Besonders sinnvoll ist das bei ETL-Strecken, Feature Engineering, Event-Verarbeitung und analytischen Workloads auf einem Data Lake.
- Nimm Spark, wenn du viele Quellen zusammenführen und große Datenmengen transformieren willst.
- Nimm Spark, wenn ein Job in Minuten oder Stunden laufen darf, dafür aber robust und skalierbar sein muss.
- Bleib bei der Datenbank, wenn es um viele kleine Transaktionen, niedrige Latenz und saubere ACID-Logik geht.
- Bleib bei der Datenbank, wenn die Datenmenge klein genug ist, dass Verteilungslogik nur Overhead erzeugt.