
Lastverteilung in Kubernetes entscheidet darüber, ob einzelne Pods unter Last ausbrennen oder ein Dienst ruhig skaliert. Beim Thema kubernetes load balancing geht es in der Praxis nicht nur um einen „Load Balancer“, sondern um das Zusammenspiel aus Service, kube-proxy, Readiness und der passenden Schicht für externen Verkehr. Genau dort liegt der Unterschied zwischen einem Cluster, der nur läuft, und einem Cluster, der auch bei Ausfällen stabil bleibt.
Die wichtigsten Punkte zur Lastverteilung im Cluster
- Intern verteilt Kubernetes über Services und EndpointSlices, nicht direkt von Pod zu Pod.
- kube-proxy setzt die Weiterleitung auf jedem Node um und wählt Backends je nach Modus und Zustand.
- Für externen Traffic sind LoadBalancer, Ingress und Gateway API verschiedene Werkzeuge mit klar unterschiedlichen Stärken.
- Readiness-Probes sind für saubere Verteilung wichtiger als viele Teams zunächst denken.
- Auf Bare Metal brauchst du meist einen Drittanbieter wie MetalLB oder einen eigenen externen Load Balancer.
- Stabilität entsteht nicht nur durch Verteilung, sondern auch durch Graceful Shutdown, Skalierung und saubere Protokollwahl.
Wie die Verteilung im Cluster intern funktioniert
Im Inneren eines Clusters verteilt Kubernetes den Verkehr nicht „magisch“, sondern über die Service-Abstraktion. Ein Service zeigt auf eine Menge von Endpunkten, meist Pods, und diese Menge wird laufend aktualisiert, sobald Pods bereit oder wieder unbrauchbar werden. Das ist im Kern ein Stabilitätsproblem, wie man es auch aus der Physik kennt: Ein System bleibt nur dann im Gleichgewicht, wenn die Last nicht an einer einzigen Stelle hängen bleibt.
Die eigentliche Weiterleitung übernimmt kube-proxy auf jedem Node. Es beobachtet Service- und EndpointSlice-Objekte und setzt die Regeln so, dass Traffic an einen passenden Backend-Pod geht. Je nach Cluster läuft das mit iptables, IPVS oder nftables; das Grundprinzip bleibt gleich, nur die Art der Umsetzung und das Skalierungsverhalten ändern sich.
Wichtig ist dabei ein Punkt, den viele anfangs unterschätzen: Kubernetes verteilt nicht einfach blind auf alle Pods. Nur Pods, die als bereit gelten, gehören überhaupt in die aktive Zielmenge. Genau deshalb sind Readiness-Probes so zentral. Ein Pod kann laufend „up“ sein und trotzdem noch kein Traffic-Ziel sein, wenn er fachlich noch nicht bereit ist.
Wenn dieser interne Pfad klar ist, stellt sich die nächste Frage: Wie kommt der Traffic überhaupt in den Cluster hinein und welche Schicht übernimmt dort die Verteilung?
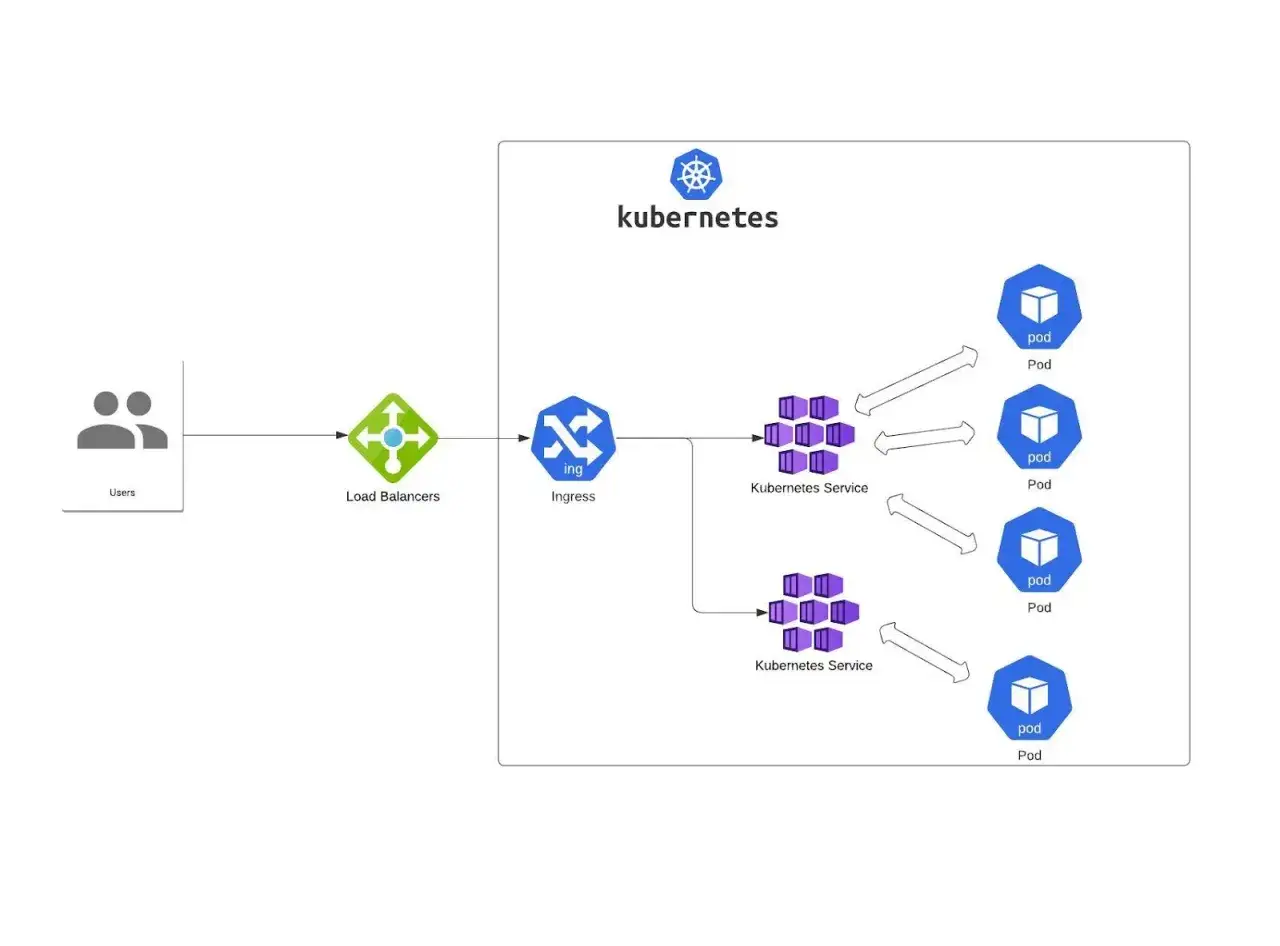
Welche Ebene den Traffic wirklich nach außen bringt
Kubernetes selbst bringt keinen eingebauten Load Balancer mit. Für externen Verkehr brauchst du entweder die Integration mit einem Cloud-Anbieter oder einen Drittanbieter-Controller. Die Unterscheidung ist wichtig, weil „Lastverteilung“ je nach Ebene etwas anderes bedeutet: mal Service-zu-Service, mal Node-zu-Pod, mal HTTP-Routing am Rand des Clusters.
| Ebene | Was sie tut | Stärken | Grenzen | Wann ich sie nutze |
|---|---|---|---|---|
| ClusterIP | Stellt einen internen stabilen Zugriffspunkt auf mehrere Pods bereit. | Einfach, robust, ideal für interne Microservices. | Kein externer Zugriff. | Für alles, was nur im Cluster sprechen soll. |
| NodePort | Öffnet einen festen Port auf jedem Node. | Schnell testbar, leicht verständlich. | Wenig elegant für produktiven Außenverkehr. | Für Debugging, Labore oder sehr einfache Exposition. |
| LoadBalancer | Bindet einen externen Load Balancer vor den Service. | Pragmatisch für Public Cloud, oft wenig Handarbeit. | Abhängig von Provider oder externem Controller. | Wenn du außen einen klaren Einstiegspunkt brauchst. |
| Ingress | Routet HTTP(S) nach Hostname und Pfad auf Services. | Gut für Webanwendungen, TLS und Host-basiertes Routing. | Im Kern HTTP(S)-zentriert. | Für klassische Web-Frontends und APIs mit vielen Routen. |
| Gateway API | Stellt moderne, rollenbasierte und erweiterbare Traffic-Regeln bereit. | Flexibler als klassisches Ingress, klarere Trennung von Rollen. | Benötigt passenden Controller und etwas mehr Planungsaufwand. | Für neue Setups, in denen Routing und Zuständigkeiten sauber wachsen sollen. |
Für Cloud-Umgebungen erledigt der Service Controller typischerweise die Anbindung an Managed Load Balancer, IP-Adressen und Health Checks. Auf Bare Metal oder in privaten Rechenzentren springt oft ein Drittanbieter ein, zum Beispiel MetalLB, damit ein LoadBalancer-ähnliches Verhalten überhaupt möglich wird. Die Kubernetes-Dokumentation empfiehlt heute bei neuen Designs eher die Gateway API als klassisches Ingress, weil sie moderner und ausdrücklicher ist.
Damit ist die Technik sauber sortiert. Die praktischere Frage lautet jetzt: Welche Variante passt zu welchem Anwendungsfall, ohne dass man später unnötig umbaut?
Wie ich die passende Variante auswähle
Ich entscheide die Schicht nie zuerst nach dem Tool, sondern nach dem Verkehr. Das spart Umbauten und verhindert, dass man ein L7-Problem mit einer L4-Lösung erschlägt oder umgekehrt.
- Interne Microservices: Ich nehme fast immer ClusterIP. Für Service-zu-Service-Kommunikation ist das die sauberste und stabilste Basis.
- Öffentliche Webanwendungen: Ich plane heute bevorzugt mit Gateway API, vor allem wenn mehrere Hosts, Pfade oder Teams im Spiel sind.
- Einfache Cloud-Exposition: Ein LoadBalancer ist oft der schnellste Weg, wenn der Provider das nativ unterstützt und keine komplexe Routing-Logik gebraucht wird.
- Bare Metal oder lokales Lab: Ich rechne mit einem externen Controller wie MetalLB oder mit vorhandener Hardware am Rand des Netzes.
- gRPC oder Mischverkehr: Ich prüfe, ob der eingesetzte Controller die benötigten Protokolle und Regeln sauber unterstützt, statt Ingress zu überladen.
Die entscheidenden Auswahlkriterien sind meist nicht kompliziert: Protokoll, Umgebung, Betriebsmodell und Kontrollbedarf. Wer nur eine schnelle Freigabe braucht, ist mit einem LoadBalancer oft schneller fertig. Wer langfristig mehrere Routen, unterschiedliche Verantwortlichkeiten und saubere Erweiterbarkeit will, landet meist bei Gateway API.
Bei HTTP gilt außerdem eine einfache Faustregel: Sobald Hostname, Pfad, TLS und mehrere Backends sauber zusammenspielen müssen, wird die reine Service-Schicht zu grob. Dann lohnt sich die zusätzliche Traffic-Ebene, weil sie Probleme strukturiert statt sie nur zu verstecken. Danach stellt sich die Frage, wie man die Verteilung stabil hält, wenn Pods starten, sterben oder überlastet werden.
Was stabile Lastverteilung wirklich verbessert
Lastverteilung allein macht ein System nicht robust. Sie verteilt nur den Verkehr, aber sie behebt weder langsame Starts noch harte Shutdowns noch zu geringe Kapazität. In meinen Augen werden hier die meisten Projekte zu optimistisch.
| Schraube | Wirkung | Typischer Nutzen | Worauf ich achte |
|---|---|---|---|
| readinessProbe | Nimmt Pods erst dann ins Routing, wenn sie wirklich bereit sind. | Verhindert 5xx-Spitzen beim Hochfahren. | Probe muss fachlich echten Betrieb abbilden, nicht nur Prozesslebenszeichen. |
| preStop + terminationGracePeriodSeconds | Gibt laufenden Verbindungen Zeit zum Auslaufen. | Weniger Abbrüche bei Deployments. | Für HTTP oft 30 bis 60 Sekunden als Startwert, bei langen Sessions eher mehr. |
| sessionAffinity | Hält denselben Client möglichst am selben Backend. | Nützlich bei statefulen Web-Flows oder Legacy-Apps. | Kann Hotspots erzeugen und echte Verteilung schwächen. |
| externalTrafficPolicy: Local | Erhält die ursprüngliche Client-IP auf externem Traffic. | Hilft bei Logging, Sicherheit und Geobasiertem Routing. | Verteilung kann ungleichmäßiger werden, wenn nicht auf jedem Node Pods laufen. |
| resources.requests/limits + HPA | Verhindert Überbuchung und skaliert bei Last nach. | Die Verteilung bleibt realistisch, nicht nur rechnerisch. | Ohne saubere Requests plant der Scheduler gern zu optimistisch. |
| PodDisruptionBudget | Schützt vor zu vielen gleichzeitigen Ausfällen. | Wichtig bei Rollouts und Node-Wartung. | Besonders relevant, wenn nur 2 oder 3 Replikas laufen. |
Für produktive HTTP-Dienste setze ich in der Regel mindestens zwei Replikas, oft drei, wenn Ausfälle oder Wartungen ohne spürbare Unterbrechung abgefangen werden sollen. Ein einzelner Pod lässt sich nicht sinnvoll „verteilen“; man verschiebt damit nur die Engstelle. Die Verteilung gewinnt erst dann wirklich an Wert, wenn genug Backends da sind, um Ausfälle und Spitzen aufzunehmen.
Damit sind die Stellschrauben klar. Trotzdem stolpern viele Cluster nicht an der Theorie, sondern an wiederkehrenden Praxisfehlern, die sich erstaunlich hartnäckig halten.
Typische Fehler, die ich in echten Clustern sehe
Die meisten Probleme entstehen nicht im Load Balancer selbst, sondern am Rand des Systems. Dort sind Signale oft uneindeutig, und kleine Fehleinschätzungen wirken sofort wie ein Netzwerkproblem.
- DNS-Round-Robin als Ersatz für Service-Verteilung: Das klingt elegant, scheitert aber an Caching, TTL-Handling und dem Verhalten von Clients.
- Liveness statt Readiness: Ein Container kann leben und trotzdem noch keine Anfragen annehmen. Wer das verwechselt, verteilt Verkehr auf halbfertige Pods.
- Nur einen Pod betreiben: Dann gibt es keine echte Lastverteilung, nur einen einzelnen Flaschenhals mit schönerer Adresse.
- NodePort direkt ins Internet hängen: Das ist selten die sauberste Betriebsform und erzeugt oft unnötige Angriffsfläche.
- Sticky Sessions als Standard: Sie lösen Zustandsprobleme nicht, sie verschieben sie oft nur in Richtung ungleicher Last.
- Kein Test für Pod- oder Node-Ausfall: Wer Ausfälle nicht aktiv simuliert, merkt die Schwachstellen meist erst im Ernstfall.
Ein weiterer Punkt ist subtiler: Viele verwechseln Load Balancing mit Kapazitätserhöhung. Das ist nicht dasselbe. Wenn deine Anwendung zu wenig CPU, zu wenig I/O oder zu lange Antwortzeiten hat, verteilt ein Service die Last nur schöner, aber nicht kleiner. Genau deshalb teste ich immer sowohl die Verteilung als auch die Engpässe dahinter.
Wenn diese Fehler vermieden sind, bleibt die eigentliche Architekturfrage: Wie würde ich heute einen neuen Cluster aufsetzen, ohne mich früh auf die falsche Schicht festzulegen?
Wie ich neue Cluster heute strukturieren würde
Für neue Setups würde ich die Rollen klar trennen: ClusterIP für interne Kommunikation, Gateway API oder einen passenden externen Load Balancer für öffentlichen Traffic und nur dort zusätzliche Komplexität, wo sie echte Probleme löst. Das hält das Netzwerkmodell verständlich und verhindert, dass jedes Team eigene Sonderwege baut.
Bei Cloud-Umgebungen ist ein verwalteter Load Balancer oft der pragmatischste Einstieg. In privaten Netzen oder auf Bare Metal würde ich früh entscheiden, ob ein Drittanbieter-Controller wie MetalLB oder eine vorhandene Perimeter-Infrastruktur die externe Rolle übernehmen soll. Erst danach würde ich Routing-Regeln, TLS und Team-Zuständigkeiten scharf ziehen.
Die wichtigste Probe für jedes Design bleibt für mich dieselbe: Was passiert, wenn ein Pod, ein Node oder eine laufende Verbindung verschwindet? Wenn die Antwort darauf sauber aussieht, ist die Verteilung nicht nur technisch korrekt, sondern auch betrieblich brauchbar. Genau an diesem Punkt wird aus Lastverteilung ein belastbares Systemdesign, und nicht nur ein weiterer Layer im Cluster.