
Eine Series in pandas lässt sich auf mehrere Arten durchlaufen, aber nicht jede Methode passt zu jedem Ziel. Beim Thema pandas iterate series geht es in der Praxis meist um die Wahl zwischen Werte-Schleife, Index-Werte-Paaren und vektorisierten Alternativen. Gerade bei Datenreinigung, Protokollierung oder kleinen Sonderlogiken entscheidet diese Wahl darüber, ob der Code klar bleibt oder unnötig langsam wird.
Die richtige Schleife hängt davon ab, ob du Werte, Index oder Leistung brauchst
-
for value in sliefert nur die Werte der Series. -
s.items()gibt dir Index und Wert als Paar und ist die richtige Wahl, wenn Labels wichtig sind. -
enumerate(s)zählt Positionen, nicht Series-Labels. -
Für Umformungen sind
map(),apply()oder direkt vektorisierte Ausdrücke meist sauberer als eine manuelle Schleife. - Während der Iteration zu schreiben ist fehleranfällig; Änderungen besser gesammelt oder vektorbasiert anwenden.
Wie pandas eine Series beim Iterieren behandelt
Eine Series ist eine eindimensionale, beschriftete Datenstruktur. Beim normalen Iterieren behandelt pandas sie aber nicht wie ein Dictionary, sondern wie ein Array: Du bekommst die Werte, nicht automatisch den Index. Das ist wichtig, weil viele Verwirrungen genau an dieser Stelle entstehen. Wer Labels braucht, muss bewusst zu einer anderen Methode greifen.
Ein einfaches Beispiel zeigt den Unterschied:
import pandas as pd
s = pd.Series([10, 20, 30], index=["a", "b", "c"])
for value in s:
print(value)
Das Ergebnis sind nur die Werte 10, 20 und 30. Wenn du dagegen wissen willst, zu welchem Label ein Wert gehört, ist die nächste Station items().
Genau an dieser Stelle lohnt sich der Blick auf die konkreten Schleifenformen im Alltag.
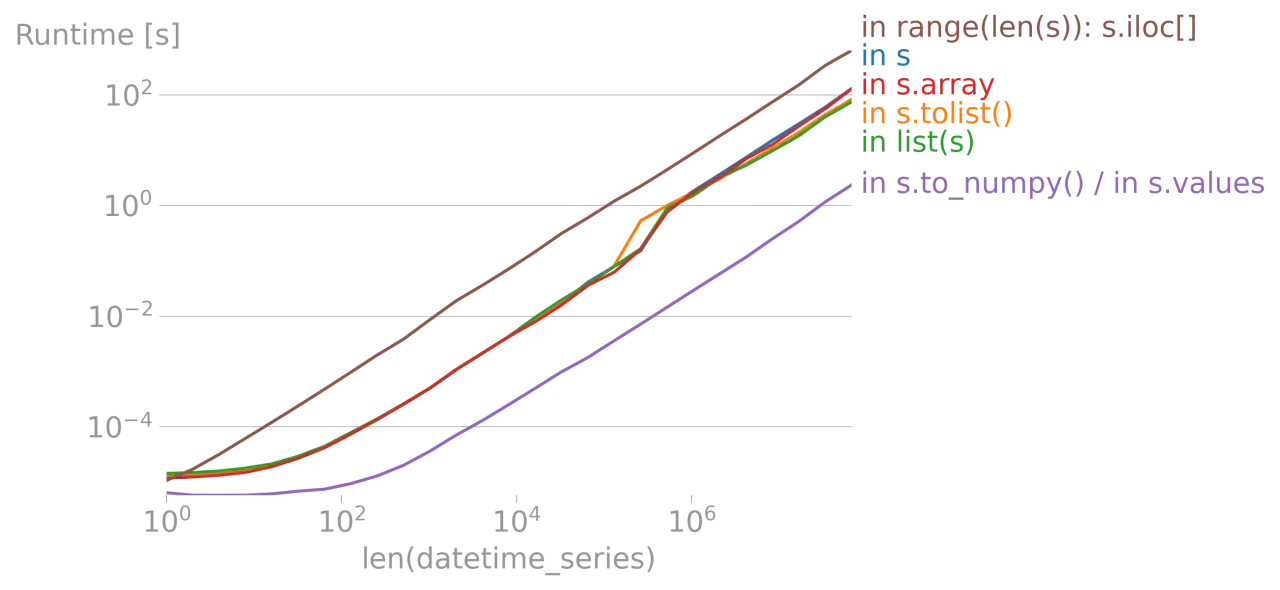
Die drei nützlichsten Schleifenformen für den Alltag
Ich trenne in Projekten fast immer nach dem Ziel der Schleife. Damit sparst du dir spätere Umbauten und vermeidest Missverständnisse zwischen Index, Position und Wert.
| Methode | Was du bekommst | Wann sie passt | Worauf du achten musst |
|---|---|---|---|
for value in s |
nur Werte | Wenn dich der Index nicht interessiert | Keine Label-Information, nur Sequenz |
for idx, value in s.items() |
Index und Wert | Wenn Labels, Zeitstempel oder Schlüssel wichtig sind | Der Index kann komplex sein, zum Beispiel ein Timestamp oder ein Tupel |
for pos, value in enumerate(s) |
Position und Wert | Wenn du Zähler brauchst, aber keine Labels | Position ist nicht dasselbe wie Series-Index |
for value in s.to_numpy() |
NumPy-Array-Werte | Wenn du nur rohe Werte brauchst | Du verlierst Series-Kontext und je nach dtype auch Speicher- oder Typvorteile |
items() ist in der aktuellen pandas-API die passende Wahl, wenn du Index und Wert gemeinsam brauchst. Die offizielle pandas-Dokumentation beschreibt genau das als lazily iterierende Methode über (index, value)-Paare. Für reine Positionszählung ist enumerate() dagegen sauberer als ein künstliches Herumrechnen mit range(len(s)).
for label, value in s.items():
print(f"{label} -> {value}")
for pos, value in enumerate(s):
print(f"{pos}: {value}")
Das wirkt unspektakulär, ist aber im Alltag oft der Unterschied zwischen lesbarem Code und späterem Debugging-Stress.
Wenn du die Schleife nur deshalb schreibst, weil du jeden Wert umformen willst, ist die Frage nach der besseren Alternative aber noch nicht beantwortet.
Wann du besser auf eine Schleife verzichtest
Die pandas-Dokumentation rät ausdrücklich dazu, iterierende Lösungen nach Möglichkeit zu vermeiden. Der Grund ist simpel: Python-Schleifen arbeiten Element für Element, während vektorisierte Operationen, NumPy-Funktionen und pandas-eigene Methoden ganze Blöcke auf einmal verarbeiten. In der Praxis ist das oft nicht nur eleganter, sondern deutlich schneller.
Ich nutze diese Faustregel:
- Einfaches Ersetzen oder Umrechnen gehört meist in eine vektorisierte Expression.
-
Ein Wert in einen anderen Wert abbilden passt gut zu
Series.map(). -
Eine einzelne Funktion auf jedes Element anwenden kann mit
Series.apply()funktionieren, wenn es keine bessere native Lösung gibt. -
Bedingte Logik lässt sich oft mit
where()odermask()sauberer ausdrücken.
# Vektorisierung
s2 = s * 2
# Bedingte Ersetzung
s3 = s.where(s >= 0, 0)
# Elementweise Abbildung
labels = s.map(lambda x: "hoch" if x >= 20 else "niedrig")
Wichtig ist die Grenze: apply() ist kein Freifahrtschein für alles. Wenn die Aufgabe auch ohne Python-Schleife in der Series lösbar ist, würde ich immer zuerst diese Variante nehmen. Gerade bei großen Datenmengen macht das einen spürbaren Unterschied, und zwar oft schneller, als man es aus kleinen Tests erwarten würde.
Bleibt eine echte Schleife übrig, dann sind die typischen Fallstricke der nächste Punkt.
Typische Fehler bei Series-Schleifen
Die meisten Probleme entstehen nicht durch die Schleife selbst, sondern durch falsche Annahmen über Index, Werte und Änderbarkeit. Diese Fehler sehe ich besonders häufig:
-
Index und Position werden verwechselt.
enumerate(s)zählt 0, 1, 2 ...; das ist nicht dasselbe wies.index. - Während der Iteration wird geschrieben. Änderungen an der gleichen Series sind fehleranfällig und sollten lieber außerhalb der Schleife erfolgen.
-
Alte Beispiele nutzen
iteritems(). In aktuellem pandas arbeitest du mititems(). -
Fehlende Werte werden ignoriert.
NaNundpd.NAbrauchen oft eine explizite Prüfung mitpd.notna(). - Der Index ist nicht eindeutig. Bei doppelten Labels oder einem MultiIndex sieht das Ergebnis schnell anders aus, als man es aus einem einfachen Beispiel kennt.
# Besser: erst sammeln, dann anwenden
updates = []
for label, value in s.items():
if pd.notna(value) and value < 0:
updates.append(label)
s.loc[updates] = 0
Das ist nicht nur robuster, sondern in vielen Fällen auch leichter zu testen als eine Schleife, die mitten im Lauf die Daten verändert. Genau deshalb lohnt sich oft ein Blick auf echte Anwendungsszenarien statt auf rein syntaktische Beispiele.
Praktische Beispiele aus der Datenarbeit
Wenn man Series in echter Arbeit durchläuft, sind die Anwendungsfälle meist deutlich konkreter als in einem Tutorial. Drei Muster tauchen besonders oft auf.
Werte protokollieren
Wenn du eine Series nur sauber ausgeben oder loggen willst, ist items() die einfachste Lösung. Besonders bei Zeitreihen oder Kategorie-Labels bleibt die Ausgabe dadurch nachvollziehbar.
for ts, value in s.items():
print(f"{ts}: {value}")
Das ist nützlich für Debugging, Audit-Logs oder kleine Reports, weil du den Zusammenhang zwischen Schlüssel und Wert direkt siehst.
Einzelwerte klassifizieren
Wenn jeder Wert in eine Kategorie fallen soll, ist map() oft die bessere Wahl als eine explizite Schleife.
kategorie = s.map(lambda x: "kritisch" if x >= 90 else "ok")
Ich nutze so etwas für Schwellenwerte, Statusmarker oder einfache Normalisierungen. Die Logik bleibt nah am Datenobjekt und verschwindet nicht in einer Schleifenstruktur.
Lesen Sie auch: Python Debugging in VS Code - Schneller & Besser Fehlersuchen
Bedingt bereinigen
Für negative Werte, Ausreißer oder fehlende Einträge ist where() bzw. mask() meist klarer als ein for-Block.
bereinigt = s.where(s >= 0, 0)
Der Vorteil ist nicht nur die Lesbarkeit. Du bekommst auch leichter konsistentes Verhalten, wenn sich die Datenstruktur später ändert oder neue Fälle dazukommen.
Solche Beispiele zeigen gut, dass Iteration zwar möglich ist, aber nicht automatisch die beste Form ist.
Welche Lösung ich im Alltag zuerst prüfe
Wenn ich eine Series bearbeite, gehe ich gedanklich immer dieselbe Reihenfolge durch: erst vektorisieren, dann map() oder apply(), und erst danach eine echte Schleife. Das spart Zeit und reduziert Fehler, weil ich die Python-Ebene nur dort einsetze, wo sie wirklich nötig ist.
-
Nur Werte lesen:
for value in soders.to_numpy() -
Index und Wert lesen:
s.items() -
Position mitzählen:
enumerate(s) -
Elementweise umformen:
map()oderapply() -
Werte bedingt ersetzen:
where()odermask()
Für mich ist das die praktischste Regel: Je weniger Logik in einer manuellen Schleife steckt, desto besser. In pandas gewinnt meistens nicht die kreativste Schleife, sondern die klarste und am stärksten vektorisierte Lösung. Wer das beim Iterieren über eine Series früh verinnerlicht, schreibt kürzeren Code, produziert weniger Nebenwirkungen und kommt bei echten Daten deutlich entspannter ans Ziel.