
Data Engineering ist die Disziplin, die Rohdaten aus Anwendungen, Datenbanken, APIs und Sensoren in belastbare Systeme für Analyse, Reporting und Machine Learning überführt. Die englische Suchfrage what is data engineering zielt im Kern genau auf diese Infrastrukturarbeit: Wie kommen Daten zuverlässig ins System, wie bleiben sie sauber, und wie werden sie so bereitgestellt, dass Entscheidungen darauf aufbauen können? Gerade an der Schnittstelle von Datenanalyse und Datenbanken zeigt sich, ob ein Unternehmen nur Daten sammelt oder daraus wirklich nutzbare Informationen macht.
Data Engineering baut die Brücke von Rohdaten zu belastbaren Entscheidungen
- Data Engineering entwirft und betreibt die Pipelines, die Daten erfassen, prüfen, transformieren und bereitstellen.
- Ohne saubere Datenflüsse werden Dashboards, Reports und Modelle schnell uneinheitlich oder unzuverlässig.
- Datenbanken, Data Warehouses und Data Lakes erfüllen unterschiedliche Aufgaben und sollten nicht verwechselt werden.
- Batch-Verarbeitung eignet sich für planbare Läufe, Streaming für nahezu sofortige Reaktionen.
- Qualität, Nachvollziehbarkeit und klare Verantwortlichkeiten sind oft wichtiger als das nächste Tool im Stack.
- In Deutschland spielen DSGVO, Zugriffskontrolle und Dokumentation eine besonders große Rolle.
Was Data Engineering eigentlich leistet
Ich betrachte Data Engineering immer als die Infrastruktur-Schicht der Datenwelt. IBM beschreibt es sinngemäß als das Design und den Aufbau von Systemen für die Aggregation, Speicherung und Analyse von Daten in großem Maßstab. Dahinter steckt keine einzelne Technik, sondern ein Zusammenspiel aus Architektur, Automatisierung, Datenmodellierung und Qualitätskontrolle.
Praktisch heißt das: Ein Data Engineer sorgt dafür, dass Daten nicht nur irgendwo ankommen, sondern auch brauchbar, aktuell und nachvollziehbar bleiben. Dazu gehören unter anderem diese Aufgaben:
- Datenquellen anbinden und neue Systeme sauber integrieren
- Rohdaten validieren und fehlerhafte Werte früh erkennen
- Formate vereinheitlichen und Geschäftslogik anwenden
- Daten speichern, versionieren und für verschiedene Nutzergruppen bereitstellen
- Metadaten, Berechtigungen und Herkunftsinformationen verwalten
Der entscheidende Punkt ist aus meiner Sicht: Data Engineering erzeugt nicht direkt Erkenntnisse, sondern die Grundlage dafür. Wenn diese Grundlage schwach ist, wird jede spätere Analyse unnötig teuer oder schlicht falsch. Genau deshalb lohnt sich der Blick auf den Datenweg vom Ursprung bis zur Auswertung.
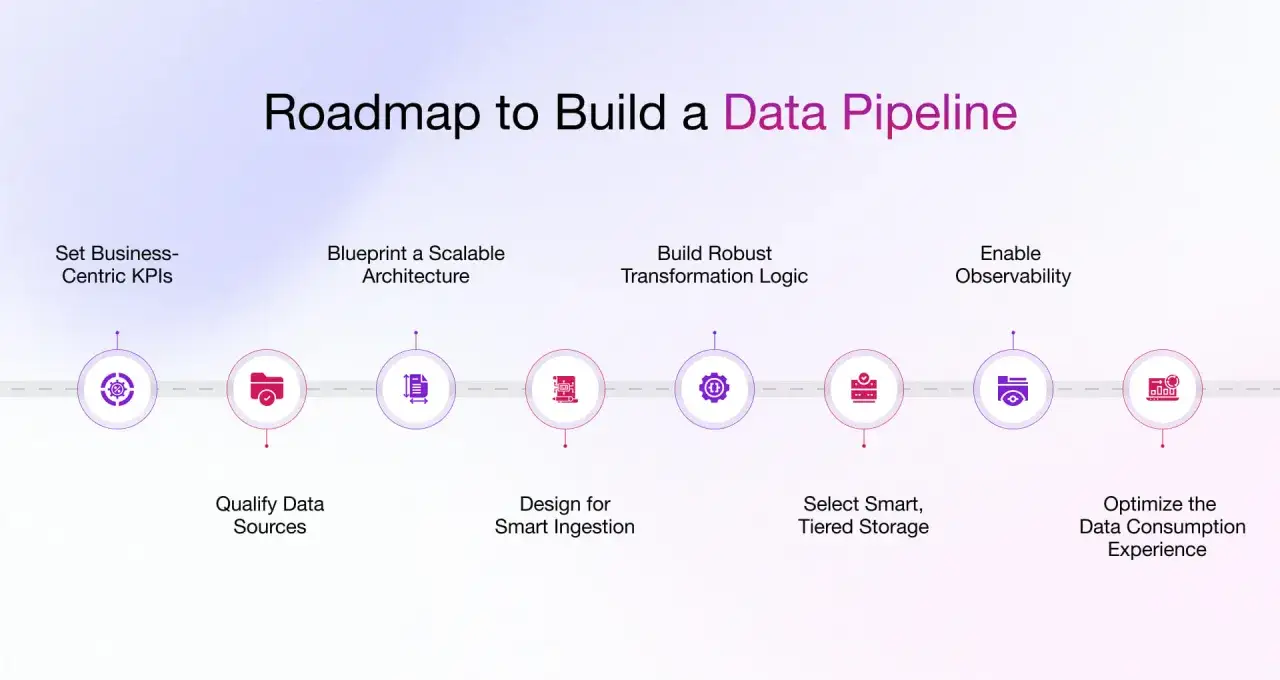
Wie Daten vom Ursprung in die Analyse kommen
AWS beschreibt eine Datenpipeline sinngemäß als Abfolge von Verarbeitungsschritten, die Rohdaten für die Analyse vorbereitet. Das ist eine gute Arbeitsdefinition, denn sie macht den Kern sichtbar: Daten werden nicht nur verschoben, sondern unterwegs geprüft, angereichert, umgeformt und an einen sinnvollen Zielort gebracht.
In der Praxis beginnt das oft mit Quellen wie operativen Datenbanken, Web-Events, CRM-Systemen, Logdateien oder IoT-Geräten. Danach folgen typischerweise Ingestion, Transformation, Speicherung und Orchestrierung. Orchestrierung bedeutet dabei schlicht: Prozesse werden gesteuert, geplant und überwacht, damit sie zuverlässig laufen und bei Fehlern nicht stillschweigend falsche Ergebnisse liefern.
| Schritt | Was passiert | Warum es wichtig ist |
|---|---|---|
| Ingestion | Daten werden aus Quellsystemen übernommen. | Ohne sauberen Import gibt es keine verlässliche Basis. |
| Transformation | Daten werden bereinigt, harmonisiert und berechnet. | Hier entsteht aus Rohdaten ein konsistentes Modell. |
| Storage | Daten landen in einem zielgerichteten Speicher wie Warehouse oder Lake. | Die Struktur bestimmt Geschwindigkeit, Kosten und Nutzbarkeit. |
| Orchestrierung | Jobs werden geplant, überwacht und bei Bedarf neu angestoßen. | So bleibt die Pipeline auch im Betrieb stabil. |
| Serving | Die Daten werden für BI, Analyse oder Modelle bereitgestellt. | Erst hier werden sie für Fachanwender wirklich nutzbar. |
Ein wichtiger Unterschied ist die Verarbeitungsart. Bei Batch-Verarbeitung laufen Daten in geplanten Intervallen, etwa alle 15 Minuten, stündlich oder einmal täglich. Streaming verarbeitet Ereignisse nahezu in Echtzeit, oft in Sekunden oder sogar Millisekunden. Batch ist meist einfacher und günstiger, Streaming dafür aktueller und für Zeitkritik wie Fraud Detection oder Live-Monitoring deutlich besser geeignet.
Ich sehe hier oft den ersten Denkfehler: Teams wählen eine Architektur, bevor sie den Fachbedarf kennen. Wer aber nur tägliche Reports braucht, braucht kein hochkomplexes Streaming-System. Sobald der Fluss steht, stellt sich die wichtigere Frage, wie die Daten sinnvoll gespeichert und modelliert werden.
Warum Datenbanken und Datenmodelle so wichtig sind
Gerade bei Datenanalyse und Datenbanken wird schnell klar, dass „Speichern“ nicht gleich „gut nutzbar machen“ ist. Eine operative Datenbank ist darauf ausgelegt, Transaktionen schnell und korrekt zu verarbeiten. Ein Data Warehouse ist dagegen für analytische Abfragen optimiert. Dazwischen liegen weitere Varianten wie Data Lakes und Lakehouses, die unterschiedliche Stärken mitbringen.
Ich trenne in Projekten immer zwischen dem Ort, an dem Daten entstehen, und dem Ort, an dem sie analytisch sinnvoll werden. Ein relationales System mit sauberem Schema ist ideal für Bestellungen, Kundenstammdaten oder Buchungen. Für große Analyseabfragen braucht es aber oft eine andere Struktur, etwa Sternschema, Dimensionstabellen oder aggregierte Schichten, damit Abfragen schnell und verständlich bleiben.
| Speicherart | Zweck | Stärke | Typische Nutzung |
|---|---|---|---|
| Operative Datenbank | Geschäftsvorfälle speichern und bearbeiten | Hohe Transaktionssicherheit | Shop, ERP, CRM, Buchungssysteme |
| Data Warehouse | Analytische Auswertungen auf bereinigten Daten | Sehr gute Abfrageleistung für BI | Management-Reports, KPI-Tracking, Controlling |
| Data Lake | Roh- und Semistrukturdaten zentral ablegen | Hohe Flexibilität bei Formaten | Logs, Events, Dateien, ML-Workloads |
| Lakehouse | Analyse und flexible Speicherung verbinden | Vereint Teile von Lake und Warehouse | Gemischte BI-, Analyse- und KI-Szenarien |
Der Unterschied liegt also nicht nur in der Technologie, sondern in der Frage, welche Arbeitslast im Vordergrund steht. Ein gutes Datenmodell reduziert Redundanz, erhöht Verständlichkeit und schützt vor widersprüchlichen Kennzahlen. Genau an dieser Stelle zahlt sich Data Engineering direkt auf die Qualität der späteren Analyse aus.
Erst wenn Speicher, Modell und Zugriff sauber zusammenspielen, können Teams mit Daten wirklich arbeiten, statt ständig über Definitionen zu streiten. Das führt direkt zur Frage, was gute Analyse von sauberem Engineering eigentlich unterscheidet.
Was gute Datenanalyse von sauberem Engineering trennt
Viele verwechseln Datenanalyse mit Data Engineering, weil beide mit denselben Daten arbeiten. Der Unterschied ist aber klar: Analyse fragt, was die Daten bedeuten. Engineering sorgt dafür, dass diese Daten überhaupt belastbar vorliegen. In der Praxis hängen beide Rollen eng zusammen, aber sie lösen unterschiedliche Probleme.
Für Analysten ist besonders wichtig, dass Kennzahlen konsistent definiert sind und dieselbe Zahl in verschiedenen Berichten nicht plötzlich anders aussieht. Wenn ein Team den Umsatz inklusive Stornos berechnet und ein anderes ohne diese Fälle, ist nicht das Dashboard das Problem, sondern die fehlende technische und semantische Disziplin im Vorfeld. Gute Pipelines sorgen deshalb für:
- einheitliche KPI-Definitionen
- frische und nachvollziehbare Datenstände
- saubere Historisierung statt kurzfristiger Exporte
- prüfbare Transformationen mit klarer Herkunft
Für mich ist das einer der wichtigsten Effekte von Data Engineering: Es spart Analysezeit, weil nicht jeder Bericht erst durch manuelle Bereinigung gerettet werden muss. Fachabteilungen können sich auf Fragen konzentrieren, statt Datenfehler hinterherzulaufen. Gerade in deutschen Unternehmen mit hohen Anforderungen an Nachvollziehbarkeit und DSGVO-Konformität ist das kein Luxus, sondern eine Grundvoraussetzung.
Wenn diese Basis steht, lohnt sich der Blick auf die Architekturen und Werkzeuge, mit denen solche Systeme heute typischerweise gebaut werden.
Welche Architekturen sich in der Praxis bewährt haben
Die konkrete Toolwahl ist wichtig, aber sie ist nicht der Ausgangspunkt. Ich beginne immer mit der Frage, wie viel Transformation vor dem Laden stattfinden soll und wie flexibel die Daten später genutzt werden müssen. Daraus ergeben sich im Wesentlichen drei häufige Muster: ETL, ELT und Lakehouse.
| Architektur | Kurz erklärt | Stärken | Grenzen |
|---|---|---|---|
| ETL | Extract, Transform, Load: erst verarbeiten, dann laden | Saubere Kontrolle, gute Governance, klassisch für Warehouses | Weniger flexibel bei sehr heterogenen Daten |
| ELT | Extract, Load, Transform: erst laden, dann im Zielsystem transformieren | Flexibel, cloudfreundlich, schnell startbar | Ohne Disziplin entstehen leicht unübersichtliche Transformationsschichten |
| Lakehouse | Ein Ansatz, der Lake und Warehouse zusammenführt | Gut für gemischte Analyse-, BI- und KI-Lasten | Komplexität bleibt, wenn Governance schwach ist |
Typische Werkzeuge sind dabei nur Mittel zum Zweck: SQL für Transformationen, Python für Automatisierung, dbt für modellierte Transformationsschichten, Airflow oder ähnliche Orchestrierungstools für die Abläufe, Kafka für Streaming und Spark für große Verarbeitungsmengen. Ich würde aber nie mit dem Tool beginnen, wenn der Datenfluss selbst noch unklar ist. Erst die Architektur, dann das Werkzeug.
Das gilt besonders deshalb, weil ein System auch dann scheitern kann, wenn die Technik formal funktioniert. Wenn die Fachseite keine klare Definition von „aktive Kunden“ hat, hilft die beste Plattform wenig. Genau dort liegen die häufigsten Fehler.
Die häufigsten Fehler in Datenprojekten
Die meisten Probleme in Datenprojekten entstehen nicht durch fehlende Rechenleistung, sondern durch fehlende Klarheit. Ein typischer Fehler ist, Produktionsdaten direkt für Reports zu verwenden, ohne Entkopplung und Qualitätsprüfung. Das spart kurzfristig Zeit, macht aber spätere Änderungen teuer und riskant.
Weitere Fehler, die ich in der Praxis immer wieder sehe, sind diese:
- Zu viele manuelle Exporte statt automatisierter Pipelines
- Keine Tests auf Nullwerte, Dubletten oder Schemaänderungen
- Unklare Zuständigkeiten für einzelne Datenprodukte
- Zu komplexe Architektur für einen noch kleinen Anwendungsfall
- Sicherheit, Zugriffsrechte und Protokollierung erst spät mitzudenken
Besonders gefährlich ist Schema Drift, also wenn sich Struktur oder Bedeutung einer Quelle unbemerkt ändern. Dann laufen Jobs scheinbar weiter, liefern aber falsche Ergebnisse. Data Engineering ist deshalb auch ein Disziplin-Thema: Beobachtbarkeit, Fehleralarme und Dokumentation sind nicht optional, sondern Teil des Systems. Wer das ignoriert, baut schnell nur eine teure Datenlandschaft ohne Verlässlichkeit.
Wenn diese Risiken vermieden werden, wird deutlich, woran gutes Data Engineering im Alltag wirklich zu erkennen ist.
Woran gutes Data Engineering im Alltag erkennbar wird
Ich erkenne gute Datenarbeit meist nicht an einer spektakulären Tool-Landschaft, sondern an der Ruhe im Betrieb. Wenn neue Quellen in einem nachvollziehbaren Prozess angebunden werden können, wenn Fehler früh sichtbar werden und wenn Fachanwender verlässliche Tabellen statt fragiler Exporte nutzen, ist das ein gutes Zeichen. Data Engineering hat dann seinen eigentlichen Zweck erfüllt: Es macht Daten belastbar, bevor jemand darauf Entscheidungen aufbaut.
Praktisch lohnt sich ein nüchterner Blick auf diese Fragen:
- Gibt es pro Datenquelle eine klare Verantwortung?
- Sind wichtige Datenqualitätsregeln automatisiert geprüft?
- Können Analysten die Herkunft einer Kennzahl nachvollziehen?
- Werden Änderungen an Quellsystemen früh erkannt?
- Ist die Architektur für den aktuellen Bedarf angemessen und nicht überladen?
Wenn ich ein neues Setup aufbauen müsste, würde ich klein beginnen: mit einer klar definierten Quelle, einem sauberen Datenmodell, wenigen, aber harten Qualitätsregeln und sauberer Dokumentation. Genau dort zeigt sich, ob Data Engineering nur ein technisches Randthema ist oder die verlässliche Grundlage für Datenanalyse, Datenbanken und moderne Entscheidungsprozesse.