
Visual Studio SQL steht in der Praxis meist für einen sauberen, projektbasierten Umgang mit Datenbankschemata: Tabellen, Views, Prozeduren und Abhängigkeiten werden wie normaler Code versioniert, geprüft und ausgerollt. Gerade bei Datenanalyse-Umgebungen ist das wertvoll, weil sich fachliche Logik, Berechtigungen und Schemaänderungen schneller im Team abstimmen lassen. In diesem Artikel ordne ich die wichtigsten Werkzeuge in Visual Studio ein, zeige einen sinnvollen Arbeitsablauf und sage auch klar, wo die Grenzen liegen.
Das Wichtigste zur SQL-Arbeit in Visual Studio in Kürze
- Die zentrale Stärke liegt nicht im bloßen Verbinden mit einer Datenbank, sondern im projektbasierten Arbeiten am Schema.
- SQL Server Object Explorer eignet sich für Browsing, schnelle Änderungen und leichte Administration direkt in der IDE.
- SQL Server Data Tools und SQL-Projekte sind die Basis, wenn Datenbankcode versioniert, gebaut und deployt werden soll.
- Schema Compare hilft, Unterschiede zwischen Projekt, Datenbank und `.dacpac` sichtbar zu machen, bevor etwas produktiv verändert wird.
- SqlPackage ist der saubere Weg für automatisierte Builds und Deployments in CI/CD-Pipelines.
- Für tiefe Administration bleibt SSMS oft stärker, während Visual Studio vor allem bei Entwicklung und Nachvollziehbarkeit punktet.
Was Visual Studio mit SQL wirklich leistet
Der eigentliche Mehrwert von Visual Studio liegt nicht darin, dass man dort einfach nur SQL-Befehle absetzen kann. Spannend wird die IDE erst dann, wenn die Datenbank als Codebasis mit Struktur, Abhängigkeiten und Build-Schritt behandelt wird. Genau das ist für Analyse-Datenbanken oft der Unterschied zwischen einem fragilen Einzelsetup und einem wartbaren Team-Workflow.
Ich nutze Visual Studio vor allem dann, wenn ein Schema reproduzierbar bleiben muss: etwa bei Tabellen für ein Data Warehouse, bei Views für fachliche Kennzahlen oder bei gespeicherten Prozeduren, die wiederholt mit demselben Verhalten ausgerollt werden sollen. Statt direkt in einer Live-Datenbank herumzuklicken, entsteht eine lokale Repräsentation des Schemas, die sich prüfen, testen und versionieren lässt. Das macht Änderungen nachvollziehbarer und reduziert Überraschungen beim Deployment.Wichtig ist aber auch die Grenze: Visual Studio ist kein vollständiger Ersatz für jedes DBA-Szenario. Für tiefere Server-Administration, Performance-Tuning oder spontane Analysen ist es meist nicht das beste Werkzeug. Die Stärke liegt klar im Entwicklungs- und Veröffentlichungsprozess rund um SQL, nicht im kompletten Ersatz eines Datenbank-Administrators. Genau deshalb lohnt sich ein Blick auf die Bausteine, die diese Arbeitsweise tragen.
Damit ist die Rolle von Visual Studio klarer: Es ist ein Entwicklungswerkzeug mit SQL-Fokus, kein reines Abfragefenster. Als Nächstes geht es um die Komponenten, die diesen Ansatz in der Praxis möglich machen.
Diese Werkzeuge machen den Unterschied
Wenn ich SQL in Visual Studio produktiv nutze, arbeite ich fast nie mit nur einem Feature. Entscheidend ist das Zusammenspiel mehrerer Werkzeuge, die jeweils einen anderen Teil des Workflows abdecken.
| Werkzeug | Wofür ich es nutze | Wichtige Grenze |
|---|---|---|
| SQL Server Object Explorer | Datenbanken verbinden, Objekte durchsehen, Tabellen bearbeiten, Abfragen starten | Praktisch für leichte Arbeit, aber nicht so tief wie ein spezialisiertes Admin-Tool |
| SQL Server Data Tools (SSDT) | SQL-Projekte anlegen, Schemata entwerfen, validieren und bauen | Der echte Nutzen entsteht erst mit sauberem Projektzuschnitt und Versionskontrolle |
| SQL Database Project | Schema als deklarative Projektstruktur pflegen und als `.dacpac` erzeugen | Das Projekt ist nicht die Laufzeitdatenbank, sondern ihr baubares Abbild |
| Schema Compare | Unterschiede zwischen Projekt, Datenbank und `.dacpac` prüfen | Vergleich ersetzt kein fachliches Review von Rename- oder Drop-Änderungen |
| SqlPackage | Builds und Deployments automatisieren, besonders in CI/CD | Für produktive Pipelines braucht es klare Regeln und getestete Publish-Profile |
| Transact-SQL-Editor | Abfragen, Skripte und Objektdefinitionen mit IntelliSense schreiben | Ohne Projektkonzept bleibt es schnell bei reinem Skripting ohne Nachverfolgbarkeit |
Für mich ist der Punkt klar: Wer nur einzelne SQL-Dateien schreibt, nutzt von Visual Studio nur einen kleinen Teil. Der echte Gewinn entsteht erst, wenn Objekte als Projekt organisiert sind und daraus ein sauberer Build- und Deploy-Mechanismus entsteht. Genau dort setzt die praktische Einrichtung an.
Wenn man die Werkzeuge auseinanderhält, wird auch die Entscheidung leichter, welches davon in welchem Teamkontext wirklich gebraucht wird. Darauf baut die konkrete Einrichtung des Projekts auf.
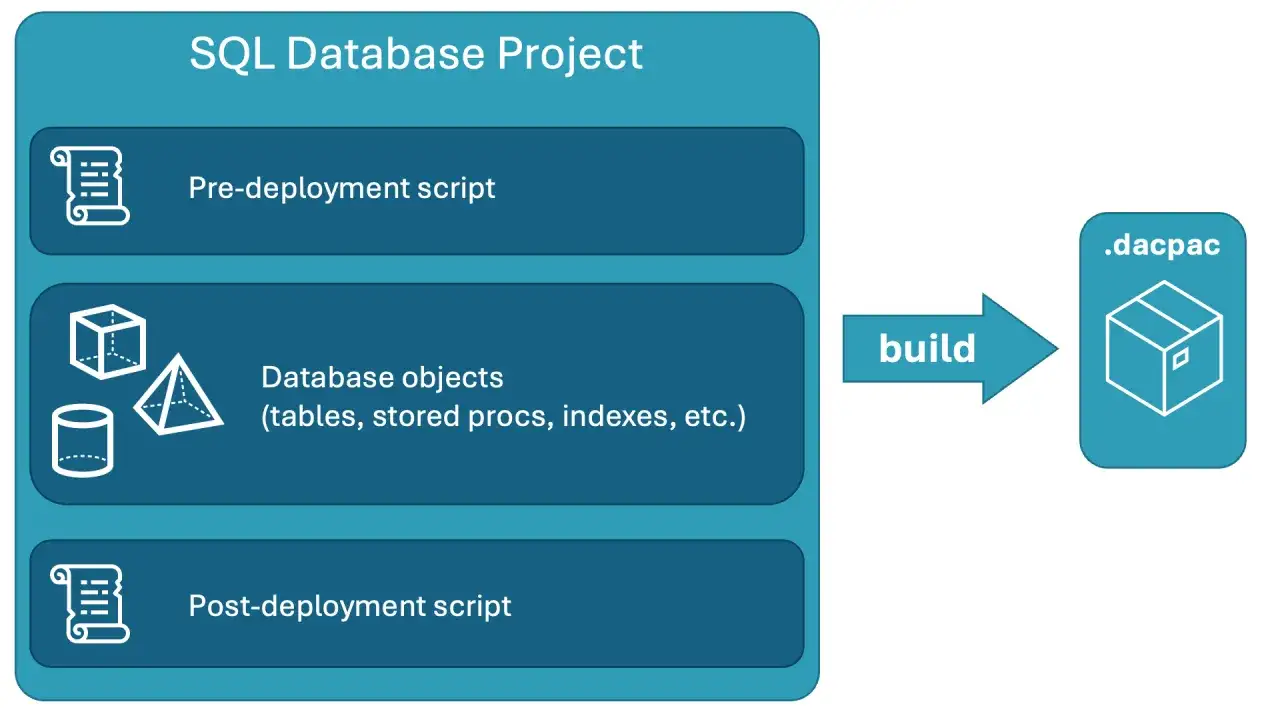
So richte ich ein SQL-Projekt sauber ein
Ein gutes Setup beginnt nicht mit dem ersten SQL-Befehl, sondern mit der Frage, was bei dir eigentlich die Quelle der Wahrheit ist. Bei neuen Analyseprojekten nehme ich meist das Schema selbst als führende Struktur. Bei bestehenden Datenbanken importiere ich zunächst, um den Bestand sauber in ein Projekt zu überführen.
- SSDT oder die SQL-Komponenten prüfen Ich stelle sicher, dass die SQL-Funktionen in Visual Studio installiert und verfügbar sind. Ohne diese Basis fehlt der projektbasierte Workflow, auf den alles andere aufsetzt.
- SQL Server Object Explorer öffnen und verbinden Damit sehe ich vorhandene Datenbanken, kann Objekte inspizieren und den Zielzustand besser einordnen. Für eine erste Bestandsaufnahme ist das oft schneller als ein separates Admin-Tool.
- SQL Database Project anlegen oder importieren Tabellen, Views, Prozeduren und andere Objekte kommen in eigene Dateien. Das klingt banal, ist aber entscheidend, weil Änderungsgründe so nachvollziehbar bleiben.
- Abhängigkeiten bewusst behandeln Wenn ein Projekt auf andere Datenbanken zugreift, arbeite ich mit Datenbankverweisen statt mit stillen Annahmen. Gerade in Analyse-Stacks mit Staging-, Reporting- und DWH-Schicht spart das später viel Zeit.
- Build früh ausführen Der Build erzeugt das `.dacpac`-Artefakt und zeigt mir, ob das Schema wirklich konsistent ist. Fehler fallen so vor dem Deployment auf, nicht erst in einer Test- oder Produktivumgebung.
- Publish-Profile für Umgebungen anlegen Entwicklung, Test und Produktion brauchen meist unterschiedliche Einstellungen. Wer hier sauber trennt, verhindert, dass versehentlich dieselben Optionen überall angewendet werden.
In Datenanalyse-Projekten ist dieser strukturierte Aufbau besonders wichtig, weil fachliche Kennzahlen oft in Views und Prozeduren stecken und nicht nur in Tabellen. Ich rate deshalb dazu, die Projektstruktur so aufzubauen, dass sie später auch von anderen Teammitgliedern verstanden wird. Was klar benannt und versioniert ist, lässt sich auch deutlich einfacher warten.
Wenn das Projekt erst einmal steht, entscheidet der nächste Schritt darüber, ob Änderungen kontrolliert oder chaotisch in die Zielumgebung gelangen. Genau dort wird Schema Compare wichtig.
Schema Compare und Publish ohne Überraschungen
Schema Compare ist eines der nützlichsten Werkzeuge, wenn ich vor einer Änderung nicht nur hoffen will, sondern konkret sehen möchte, was sich ändern würde. Der Vergleich kann zwischen Projekt, Datenbankverbindung und `.dacpac` erfolgen. Das ist praktisch, wenn ich prüfen will, ob mein lokales Projekt noch zum realen Zustand passt oder ob ein Deployment Folgeänderungen mit sich bringt.
Besonders hilfreich finde ich, dass Vergleichsdefinitionen als `.scmp`-Datei gespeichert werden können. So muss man dieselben Optionen nicht bei jedem Lauf neu setzen, und das Team kann denselben Vergleich reproduzieren. Die Ergebnisse zeigen Unterschiede typischerweise gruppiert nach Aktion, also etwa Hinzufügen, Ändern oder Löschen. Genau an dieser Stelle wird sichtbar, ob eine Änderung harmlos ist oder potenziell riskant.
Beim Publish ist für mich die wichtigste Regel: Nie blind ausrollen. Die Veröffentlichung aktualisiert die Ziel-Datenbank schrittweise so, dass sie dem Quellzustand entspricht. Das ist gut, weil es kontrolliert geschieht. Es bleibt aber trotzdem ein operativer Eingriff, der geprüft werden muss. Wenn in einem Deploymentpaket auch Daten enthalten sind, kann das die Inhalte bestehender Tabellen überschreiben. Für produktive Systeme gehört deshalb immer ein geprüftes Skript oder mindestens ein bewusst kontrolliertes Publish-Profil dazu.
Ein Detail, das gern übersehen wird, sind Datenbankoptionen. Projekt-Properties können während des Publizierens auch Datenbankeinstellungen verändern. Wenn das nicht gewünscht ist, sollte man die entsprechenden Publish-Properties bewusst setzen. Genau solche kleinen Einstellungen entscheiden oft darüber, ob ein Deployment sauber oder unerwartet wird.
Der praktische Wert von Schema Compare liegt also nicht nur im technischen Vergleich, sondern im besseren Urteil vor dem Deployment. Wenn dieser Schritt sitzt, stellt sich die nächste Frage fast automatisch: Muss es überhaupt immer Visual Studio sein?
Wann Visual Studio, SSMS oder Azure Data Studio besser passt
Ich sehe diese Werkzeuge nicht als Konkurrenz, sondern als verschiedene Antworten auf unterschiedliche Aufgaben. Wer sie sauber trennt, arbeitet effizienter und macht weniger Kompromisse, als wenn alles in einem einzigen Tool erledigt werden soll.
| Werkzeug | Stark bei | Weniger geeignet für |
|---|---|---|
| Visual Studio | Projektbasierte SQL-Entwicklung, Versionskontrolle, Build und Deployment | Spontane DBA-Arbeit und tiefes Server-Tuning |
| SSMS | Verwaltung, Diagnose, Server- und Datenbankadministration, detaillierte Eingriffe | Sauberer Code- und Projektworkflow über mehrere Dateien hinweg |
| Azure Data Studio | Leichte Abfragen, Notebook-nahe Analyse, schlanke Oberfläche | Komplexe Projektverwaltung und umfangreiche Schema-Workflows |
Für Analyse-Teams ist die Kombination oft am sinnvollsten: Visual Studio für das strukturierte Schema, SSMS für tiefere Eingriffe und Azure Data Studio, wenn eine schnelle, schlanke Abfrage- oder Analyseoberfläche genügt. Ich würde nie behaupten, dass ein einzelnes Tool alles besser kann. In der Praxis gewinnt meistens die Kombination, die die jeweilige Aufgabe am wenigsten kompliziert macht.
Damit ist auch klar, dass die Frage nicht lautet, welches Werkzeug „das beste“ ist, sondern welches das passende ist. Aus dieser Entscheidung entstehen dann die typischen Fehler, die ich in Projekten immer wieder sehe.
Typische Fehler, die in Datenbankprojekten Zeit kosten
Die meisten Probleme in SQL-Projekten entstehen nicht durch das Tool selbst, sondern durch einen unklaren Prozess. Genau dort lohnt sich etwas Disziplin mehr als noch eine weitere Erweiterung.
- Die Live-Datenbank wird zur eigentlichen Quelle der Wahrheit. Sobald Änderungen direkt in Produktion passieren und nicht im Projekt landen, verliert man Nachvollziehbarkeit.
- Schema-Dateien werden nicht versioniert. Ohne Git oder ein anderes VCS fehlt die Historie, und Rücksprünge werden unnötig teuer.
- Schema Compare wird ohne Review verwendet. Ein Vergleich ist nur dann hilfreich, wenn man die Unterschiede fachlich versteht und nicht blind übernimmt.
- Umbenennungen werden unterschätzt. Ein Rename kann im Vergleich schnell wie Löschen und Neuerstellen aussehen. Wer das nicht prüft, riskiert Nebeneffekte.
- Datenbankoptionen und Referenzen werden ignoriert. In komplexeren Umgebungen sind diese Einstellungen oft genauso wichtig wie Tabellen und Views selbst.
- Preview-Funktionen werden wie stabile Kernfunktionen behandelt. Das gilt besonders dann, wenn Build- oder Deploy-Pipelines darauf aufbauen sollen.
Ich beobachte außerdem oft, dass Teams logische Änderungen und Datenbewegungen in einen einzigen Schritt pressen. Das spart im Moment Zeit, rächt sich aber später bei Fehlersuche und Rollback. Sauberer ist es, Schema, Daten und Deployment getrennt zu denken. Dann wird jede Änderung leichter prüfbar.
Wer diese Fehler vermeidet, landet automatisch bei einem stabileren Setup. Genau darauf kommt es bei produktiven Datenbankprojekten am Ende an.
Worauf ich bei produktiven Datenbankprojekten zuerst achte
Wenn ich ein SQL-Setup in Visual Studio beurteilen muss, achte ich zuerst auf fünf Punkte: Gibt es eine klare Quelle der Wahrheit, sind Deployments prüfbar, sind Referenzen sichtbar, sind Umgebungen getrennt und ist der Code lesbar genug, dass ein anderes Teammitglied ihn morgen noch versteht?
- Das Projekt ist das führende Artefakt, nicht die zufällig veränderte Datenbank.
- Jedes Deployment erzeugt ein nachvollziehbares Skript oder einen klaren Publish-Prozess.
- Views, Prozeduren und andere fachliche Logik sind sauber getrennt und benannt.
- Verweise auf andere Datenbanken oder Plattformen sind explizit modelliert.
- Entwicklungs-, Test- und Produktionsprofile unterscheiden sich bewusst, nicht zufällig.
Wenn diese Basis steht, wird Visual Studio zu einem sehr brauchbaren Ort für SQL-Entwicklung und Datenanalyse-nahe Datenbankarbeit. Der große Vorteil ist nicht die Oberfläche selbst, sondern die Disziplin, die sie im Projekt erzwingt: weniger Handarbeit, mehr Nachvollziehbarkeit und deutlich weniger Überraschungen beim nächsten Deploy.