
Ein Data Mart ist die schlankere Antwort auf eine sehr konkrete Analysefrage: Wie bekommen Fachbereiche genau die Daten, die sie für Entscheidungen brauchen, ohne sich durch den gesamten zentralen Datenbestand zu arbeiten? In diesem Artikel zeige ich, was ein Data Mart ist, wie er sich von Data Warehouse und Data Lake unterscheidet, welche Varianten es gibt und woran ich ein brauchbares Design in der Praxis erkenne. Gerade in Datenanalyse und Datenbanken ist das wichtig, weil hier viele spätere Reporting-Probleme entstehen oder eben vermieden werden.
Die wichtigsten Punkte zu Data Marts
- Ein Data Mart ist ein fachlich abgegrenzter Ausschnitt einer größeren Datenplattform, meist für Vertrieb, Marketing, Finance oder Operations.
- Er ist kleiner als ein Data Warehouse und stärker auf konkrete Kennzahlen, Berichte und Dashboards zugeschnitten.
- Es gibt abhängige, unabhängige und hybride Data Marts - der Unterschied liegt vor allem in der Quelle und in der Governance.
- Der technische Kern ist oft ein dimensionales Modell, häufig mit Sternschema sowie klaren Fakt- und Dimensionstabellen.
- Ohne saubere KPI-Definitionen und Verantwortlichkeiten kann ein Data Mart eher neue Silos schaffen als echte Klarheit.
Was ein Data Mart in der Praxis ist
Ein Data Mart ist eine fachlich abgegrenzte Datensicht, die für ein bestimmtes Team oder einen bestimmten Geschäftsbereich optimiert ist. Er enthält nicht einfach nur weniger Daten, sondern vor allem die Daten, die für einen klaren Zweck modelliert, bereinigt und schnell auswertbar gemacht wurden. Genau das macht den Unterschied zu einer beliebigen Tabellenkopie in einer Datenbank.
Ich unterscheide dabei streng zwischen bloßer Datenablage und einer echten Analyseebene: Ein Data Mart beantwortet wiederkehrende Fragen, nicht jedes denkbare Detail. Deshalb enthält er oft bereits harmonisierte Stammdaten, definierte Kennzahlen und eine Struktur, die Analysten ohne lange Vorarbeit verstehen können. Wer ihn nur als Mini-Datenbank sieht, verfehlt seinen eigentlichen Nutzen.
Abhängig, unabhängig oder hybrid
Ein abhängiger Data Mart bezieht seine Daten aus einem zentralen Data Warehouse. Das ist meist die sauberste Variante, wenn Unternehmen bereits ein stabiles zentrales Modell haben, weil Kennzahlen und Stammdaten konsistenter bleiben.
Ein unabhängiger Data Mart zieht Daten direkt aus Quellsystemen. Das kann schnell sein und für kleinere Teams durchaus funktionieren, bringt aber häufiger Doppelungen und abweichende Definitionen mit sich.
Der hybride Data Mart kombiniert beide Wege. Ich halte ihn dann für sinnvoll, wenn ein zentrales Warehouse existiert, aber ein Fachbereich zusätzliche externe oder sehr lokale Daten braucht. Für kleinere Organisationen kann ein unabhängiger Mart ein pragmatischer Einstieg sein, bei mehreren Fachbereichen gewinnt langfristig oft die abhängige oder hybride Variante.
Welche Variante sinnvoll ist, hängt vor allem von Governance und Reifegrad der gesamten Datenlandschaft ab. Genau dort setzen die praktischen Vorteile an.
Warum ich Data Marts in Analyseprojekten oft vorziehe
Ich setze Data Marts vor allem dort ein, wo ein Fachbereich dieselben Kennzahlen immer wieder braucht und die Antwortzeit für Berichte und Dashboards spürbar zählt. Das ist weniger eine Frage des Hypes als eine Frage der Arbeitsrealität: Wer jeden Morgen dieselben Umsätze, Conversion-Raten oder Bestände prüft, braucht eine Datenbasis, die genau darauf zugeschnitten ist.
- Schnellere Auswertung - weil nur ein fokussierter Datenbestand abgefragt wird.
- Weniger Komplexität - weil Fachanwender nicht durch unnötige Tabellen oder Nebendaten navigieren müssen.
- Einheitliche Fachsprache - weil Umsatz, Marge oder Conversion zentral definiert werden können.
- Bessere Steuerbarkeit - weil Zugriffe und Verantwortlichkeiten enger geschnitten sind.
- Geringere Einstiegshürde - weil Teams schneller mit ihren eigenen Reports arbeiten können.
Der Nutzen zeigt sich besonders bei Vertrieb, Marketing, Controlling oder Operations, also überall dort, wo wiederkehrende Entscheidungen auf klar definierte Kennzahlen angewiesen sind. Genau hier trennt sich ein echter Analysebereich von einer bloßen Kopie von Quellsystemdaten. Wie diese Vorteile technisch erreichbar werden, zeigt der nächste Abschnitt.
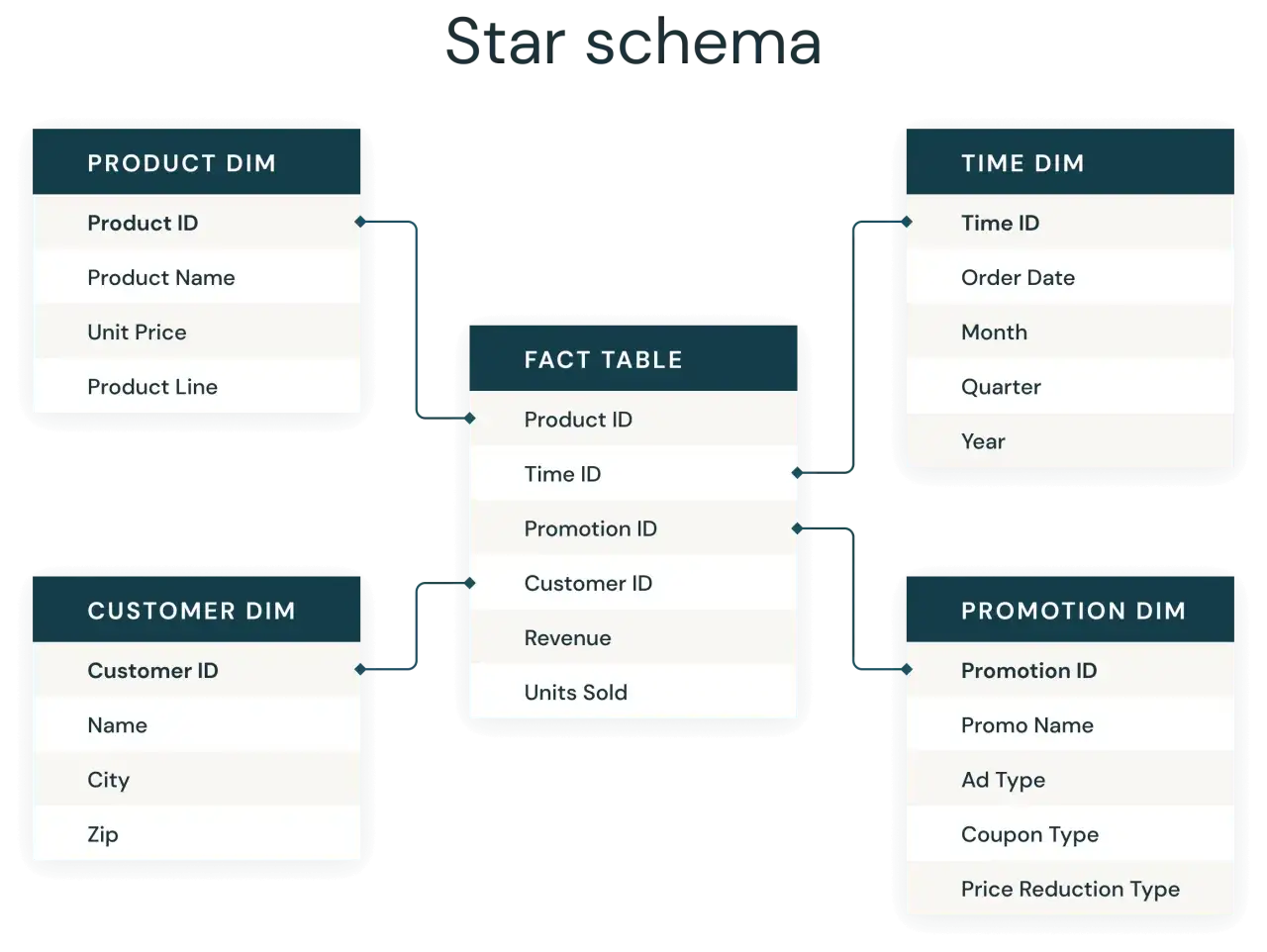
Wie ein Data Mart technisch sauber aufgebaut wird
Wenn ich ein Modell entwerfe, denke ich zuerst an die fachliche Frage und erst dann an die Tabellenstruktur. In der Praxis landet man oft bei dimensionaler Modellierung: Das ist ein Datenmodell, das Messwerte und beschreibende Merkmale trennt, damit Abfragen leichter verständlich und meist auch schneller werden.
Das Sternschema als pragmatischer Standard
Das Sternschema besteht aus einer zentralen Faktentabelle und mehreren Dimensionstabellen. Die Faktentabelle enthält die Ereignisse oder Kennzahlen, also etwa Bestellungen, Umsätze oder Tickets; die Dimensionstabellen liefern den Kontext dazu, zum Beispiel Kunde, Produkt, Region oder Zeit.
Ich mag diese Struktur, weil sie im Alltag gut erklärbar bleibt. Ein Fachanwender versteht schneller, woher eine Zahl kommt, und ein Analyst muss nicht jedes Mal ein komplexes Beziehungsgeflecht auseinandernehmen.
Lesen Sie auch: Data-Mining-Prozess - So gelingen Ihre Analysen wirklich
So gehe ich beim Aufbau vor
- Ich kläre zuerst die eine oder wenigen Fachfragen, die der Mart beantworten soll.
- Danach lege ich fest, welche Kennzahlen, Zeitbezüge und Dimensionen zwingend gebraucht werden.
- Dann prüfe ich die Datenquellen, ihre Qualität und den Aktualisierungsrhythmus.
- Anschließend entscheide ich, ob ETL oder ELT besser passt. ETL bedeutet, dass Daten vor dem Laden bereinigt und umgeformt werden; ELT verschiebt Teile der Transformation in das Zielsystem.
- Zum Schluss dokumentiere ich Berechtigungen, Datenherkunft und Verantwortlichkeiten. Ohne das kippt der Mart später in ein schwer wartbares Schattenprojekt.
Diese Reihenfolge wirkt nüchtern, ist aber in der Praxis der Unterschied zwischen einem belastbaren Analysewerkzeug und einem hübsch benannten Datenstapel. Der nächste Schritt ist daher der Blick auf die Abgrenzung zu den benachbarten Architekturbausteinen.
Data Mart, Data Warehouse und Data Lake im Vergleich
Die Begriffe werden oft durcheinandergeworfen, obwohl sie in der Datenarchitektur unterschiedliche Aufgaben erfüllen. Für mich ist die einfachste Einordnung: Das Warehouse ist die zentrale, integrierte Analysebasis, der Data Mart ist die fachliche Zuschnittsebene, und der Data Lake ist der flexiblere Speicher für rohe oder nur leicht vorbereitete Daten.
| Kriterium | Data Warehouse | Data Mart | Data Lake |
|---|---|---|---|
| Zweck | Unternehmensweite Analyse und Integration | Fokussierte Sicht für einen Fachbereich | Aufnahme vieler Datenarten für spätere Verarbeitung |
| Datenzustand | Bereinigt, harmonisiert und historisiert | Kuratiert, oft aggregiert und fachlich zugeschnitten | Roh bis leicht aufbereitet |
| Typische Nutzer | Viele Teams, BI, Data Engineering, Management | Vertrieb, Marketing, Finance, Operations | Data Engineers, Data Scientists, Plattformteams |
| Stärke | Einheitliche Unternehmenssicht | Schnelle, verständliche Fachanalysen | Hohe Flexibilität bei Datenformaten |
| Risiko | Komplexität und längere Einführungszeit | Silos bei zu vielen Einzelmarts | Unordnung ohne klare Governance |
Wichtig ist mir dabei ein Punkt, den viele im ersten Entwurf übersehen: Diese Bausteine schließen sich nicht aus. In reifen Umgebungen ergänzen sie sich, weil sie unterschiedliche Ebenen derselben Datenstrategie abdecken. Genau diese Wechselwirkung macht die Architektur später robuster.
Typische Fehler, die den Nutzen schnell ausbremsen
Ich sehe in Projekten immer wieder dieselben Muster. Der Data Mart wird angekündigt als Lösung für Transparenz, endet aber als zusätzliche Kopie von Daten, die niemand mehr sauber pflegt.
- Zu viele Marts für dieselbe Fachlogik - wenn Vertrieb, Controlling und Marketing dieselbe Kennzahl unterschiedlich bauen, entstehen widersprüchliche Dashboards.
- Unklare Definitionen - Begriffe wie aktiver Kunde oder qualifizierter Lead müssen fachlich eindeutig festgelegt sein, sonst verliert der Mart Vertrauen.
- Zu viel Rohdatenlast - ein Data Mart soll vereinfachen, nicht das Warehouse oder den Lake komplett nachbauen.
- Schwache Datenqualität - fehlerhafte Stammdaten, fehlende Historie oder unklare Zeitlogik machen aus einer guten Idee schnell ein Reportingproblem.
- Kein Ownership-Modell - ohne klare Zuständigkeiten ist nach wenigen Monaten offen, wer Kennzahlen, Ladeprozesse und Berechtigungen eigentlich pflegt.
Der wichtigste Schutz dagegen ist Disziplin im Zuschnitt. Ein Data Mart braucht eine klare Grenze, sonst wird er genau zu der Komplexität, die er eigentlich reduzieren sollte. Deshalb lohnt sich am Ende ein nüchterner Produktivitätscheck.
Woran ich einen Data Mart für produktiv halte
Bevor ich einen Data Mart live ziehe, prüfe ich im Kern vier Dinge: Ist die Fachfrage klar? Sind die Kennzahlen dokumentiert? Ist die Herkunft der Daten nachvollziehbar? Und gibt es jemanden, der den Mart fachlich und technisch verantwortet? Wenn eine dieser Antworten wackelt, verschiebe ich den Go-live lieber, statt später Vertrauen in die Zahlen zu verlieren.
- Die Nutzer können die wichtigsten Kennzahlen ohne Interpretationsspielraum lesen.
- Die Ladeprozesse sind reproduzierbar und überwacht.
- Die Zugriffsrechte passen zum Informationsbedarf des Fachbereichs.
- Neue Anforderungen führen nicht sofort zum Wildwuchs, sondern zu einer sauberen Erweiterung.
Wenn diese Bedingungen erfüllt sind, ist ein Data Mart kein Luxusbaustein, sondern ein sehr wirksames Instrument für fokussierte Analyse. Genau deshalb bleibt das Konzept auch in modernen Datenlandschaften relevant: Nicht jede Frage braucht den gesamten Unternehmensdatensatz, aber jede gute Analyse braucht eine klare fachliche Sicht.