
Die Essenz von OLAP in wenigen Punkten
- OLAP macht aus großen Datenbeständen eine schnell abfragbare Analysebasis für BI, Controlling und Forecasting.
- Im Zentrum stehen Dimensionen, Kennzahlen und saubere Hierarchien, nicht einzelne Datensätze.
- Typische Arbeitsschritte sind drill-down, roll-up, slice, dice und pivot.
- OLAP ist für Analysen gebaut, OLTP für Transaktionen; beides in einem System kostet oft Performance und Klarheit.
- ROLAP, MOLAP und HOLAP lösen dieselbe Aufgabe unterschiedlich und bringen eigene Trade-offs mit.
Was OLAP im Kern leistet
Ich verstehe OLAP nicht als einzelnes Produkt, sondern als Art, analytische Fragen zu modellieren und schnell zu beantworten. Die Idee ist simpel: Daten werden für wiederkehrende Auswertungen vorbereitet, verdichtet und nach fachlichen Blickwinkeln organisiert. So entsteht eine Struktur, in der ich nicht nur den Monatsumsatz sehe, sondern gleichzeitig nach Region, Produktgruppe oder Kanal umschalten kann.
Das ist der Grund, warum OLAP in Data Warehouses und Data Marts so gut funktioniert. Die Systeme sind auf Lesen, Vergleichen und Zusammenfassen ausgelegt, nicht auf dauerndes Hin- und Herschreiben einzelner Buchungen. Für Controlling, Business Intelligence (BI) und Forecasting ist genau das der richtige Fokus, weil dort selten der eine Datensatz zählt, sondern die verlässliche Sicht auf viele Datensätze zusammen.
Damit die Idee nicht abstrakt bleibt, lohnt sich ein Blick auf den technischen Ablauf dahinter.
Wie die Auswertung technisch abläuft
In der Praxis beginnt OLAP nicht mit der Abfrage, sondern mit der Datenaufbereitung. Quellen wie ERP, CRM, Shop-Systeme oder Maschinenlogs werden über ETL/ELT zusammengeführt. ETL/ELT bedeutet, dass Daten entweder vor dem Laden oder direkt im Zielsystem bereinigt und transformiert werden. Häufig landet das in einem Sternschema: eine zentrale Faktentabelle enthält die Messwerte, die umliegenden Dimensionstabellen liefern den fachlichen Kontext. Bei stärker normalisierten Dimensionen spricht man von einem Schneeflockenschema.
Für die eigentliche Analyse werden je nach Plattform Aggregattabellen, materialisierte Sichten, Caches oder multidimensionale Speicherstrukturen genutzt. Der Punkt ist immer derselbe: Rechenarbeit wird möglichst weit nach vorne verlagert, damit die Abfrage später schnell reagieren kann. Das ist besonders wichtig, wenn mehrere Nutzer gleichzeitig dieselben Kennzahlen mit unterschiedlichen Filtern sehen wollen.
| Operation | Wirkung | Beispiel |
|---|---|---|
| Drill-down | Von einer groben auf eine feinere Ebene wechseln | Vom Jahresumsatz auf den Monatsumsatz zoomen |
| Roll-up | Feine Daten wieder verdichten | Mehrere Monate zu einem Quartal zusammenfassen |
| Slice | Eine Dimension auf einen Wert festnageln | Nur die Region Süd betrachten |
| Dice | Mehrere Dimensionen gleichzeitig filtern | Region Süd, Produktgruppe A und Q2 auswählen |
| Pivot | Die Sichtachse der Analyse drehen | Regionen statt Produktgruppen in den Spalten anzeigen |
Die Begriffe klingen nach Fachjargon, beschreiben aber einen sehr alltäglichen Ablauf: erst einen Überblick, dann tiefer in die Details. Genau dafür ist das Würfelmodell nützlich.
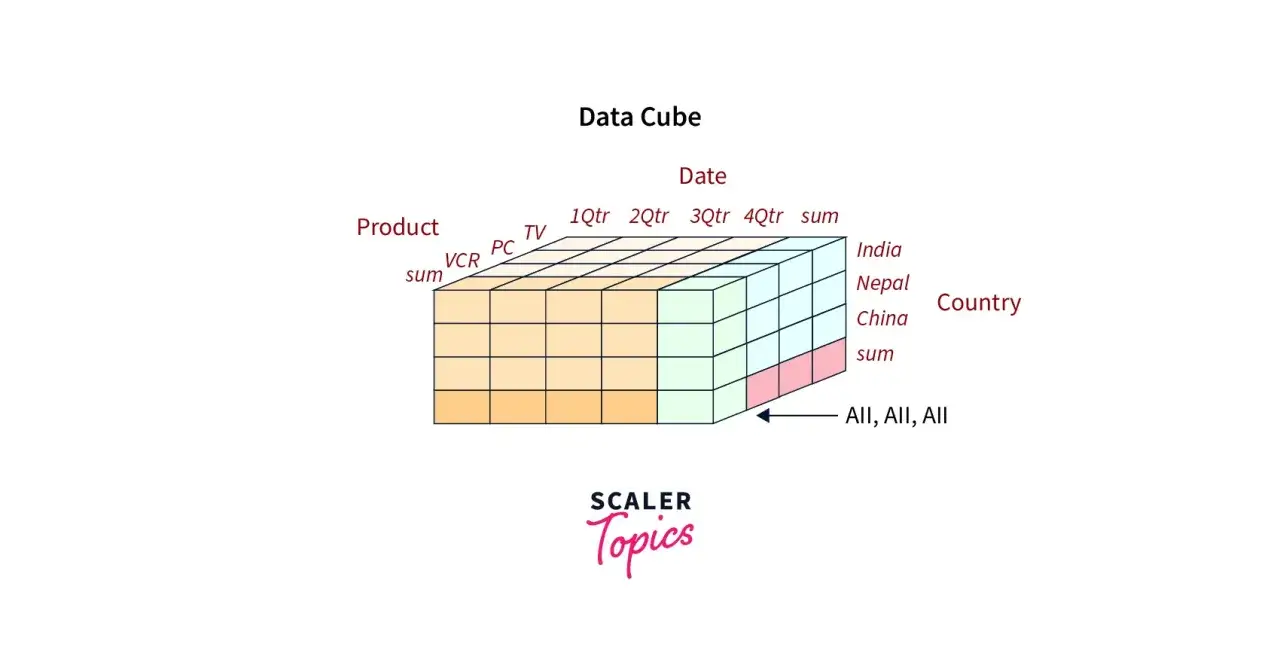
Dimensionen, Kennzahlen und der Würfelgedanke
Der Würfel ist vor allem ein Denkmodell. Er steht dafür, dass ich eine Kennzahl über mehrere Achsen gleichzeitig betrachte, zum Beispiel über Zeit, Region, Produkt und Vertriebskanal. In drei Dimensionen lässt sich das noch gut visualisieren, in der Realität kommen aber oft mehr fachliche Blickwinkel dazu.
| Element | Bedeutung | Beispiel | Praxisrelevanz |
|---|---|---|---|
| Dimension | Fachlicher Blickwinkel auf die Daten | Zeit, Region, Produkt, Kunde | Bestimmt, wie ich die Ergebnisse schneiden kann |
| Hierarchie | Stufen innerhalb einer Dimension | Jahr > Quartal > Monat > Tag | Macht Drill-down und Roll-up erst sinnvoll |
| Kennzahl | Messgröße, die ausgewertet wird | Umsatz, Kosten, Menge, Marge | Sollte eindeutig definiert und technisch prüfbar sein |
| Fakt | Konkretes Ereignis oder Beobachtung | Bestellung, Rechnung, Messwert | Bestimmt die Granularität des Modells |
| Additivität | Ob sich eine Kennzahl sinnvoll aufsummieren lässt | Umsatz ja, Quote nein | Entscheidet über richtige Aggregationen |
Besonders wichtig ist die Additivität einer Kennzahl. Umsatz lässt sich meist sauber aufsummieren, ein Bestand ist über Zeit schon heikler, und Quoten oder Margen darf man nicht einfach blind addieren. Genau hier scheitern viele Modelle, obwohl die Datenbank technisch sauber gebaut ist.
Wenn die fachlichen Achsen stehen, stellt sich als Nächstes die Frage, wie sich OLAP von operativen Systemen abgrenzt.
Warum OLAP und OLTP nicht gegeneinander antreten
OLAP und OLTP werden oft in einen Topf geworfen, obwohl sie verschiedene Aufgaben haben. OLTP verarbeitet Transaktionen im Tagesgeschäft, also etwa Bestellungen, Zahlungen oder Buchungen. OLAP verdichtet diese Daten später für Analysen, Vergleiche und Planungen.
| Aspekt | OLAP | OLTP |
|---|---|---|
| Ziel | Analysieren, vergleichen, planen | Buchen, ändern, bestätigen |
| Abfragen | Komplex, aggregiert, häufig leselastig | Kurz, punktgenau, transaktionsorientiert |
| Datenmodell | Oft dimensional oder stark auswertungsorientiert | Meist normalisiert und auf Konsistenz ausgelegt |
| Lastprofil | Weniger Schreibvorgänge, dafür viele Auswertungen | Viele kleine Schreib- und Lesezugriffe |
| Beispiel | Umsatz nach Region und Monat | Kundenauftrag abschließen |
In gemeinsamen Systemen kollidieren diese Profile schnell. Eine schwere Analyseabfrage kann Indizes, Cache und Sperrlogik stören, während laufende Transaktionen die Analyse ausbremsen. Deshalb trenne ich operative und analytische Datenbanken in Projekten fast immer, selbst wenn beide aus derselben Quelle gespeist werden.
Welche technische Form OLAP annimmt, hängt dann vom Datenvolumen, von der Aktualität und vom gewünschten Antwortzeit-Ziel ab.
Welche OLAP-Varianten in der Praxis zählen
Die drei klassischen Spielarten unterscheiden sich vor allem darin, wo die analytische Struktur lebt. Das ist keine akademische Unterscheidung, sondern beeinflusst Speicherbedarf, Geschwindigkeit und Wartung sehr direkt.
| Variante | Wie sie arbeitet | Stärken | Grenzen |
|---|---|---|---|
| ROLAP | Analysen direkt auf relationalen Tabellen | Skaliert gut, passt zu bestehenden Warehouses, flexibel bei großen Datenmengen | Kann bei sehr komplexen Aggregationen langsamer sein |
| MOLAP | Daten werden in multidimensionalen Strukturen vorverdichtet | Sehr schnelle Abfragen, starke Analyseperformance | Mehr Speicherbedarf, aufwendigere Pflege bei großen Modellen |
| HOLAP | Kombiniert relationale und multidimensionale Teile | Guter Kompromiss aus Reichweite und Tempo | Komplexer im Betrieb und in der Modellierung |
In modernen Plattformen sehe ich oft Mischformen statt sauberer Lehrbucharchitektur. Spaltenorientierte Warehouses, semantische Schichten und materialisierte Aggregationen übernehmen heute viele Aufgaben, die früher ein klassischer OLAP-Server erledigt hat. Entscheidend ist am Ende nicht das Etikett, sondern ob die Kennzahlen schnell, nachvollziehbar und konsistent verfügbar sind.
Doch selbst ein gutes technisches Setup scheitert, wenn das Modell fachlich unsauber ist.
Woran gute Analysemodelle in der Datenbankpraxis scheitern
Die meisten Probleme entstehen nicht im Query-Optimizer, sondern vor der ersten Abfrage. Ich sehe immer wieder dieselben Fehler: Kennzahlen sind unterschiedlich definiert, Granularitäten werden vermischt oder Dimensionen ändern sich ohne historisches Konzept. Genau dort verliert ein Reporting-System seine Glaubwürdigkeit.
- Unklare Kennzahlen - Wenn Vertrieb und Controlling Umsatz unterschiedlich zählen, hilft auch die beste Datenbank nicht.
- Falsche Granularität - Ein Modell auf Tagesebene taugt nicht automatisch für Belege, und umgekehrt fehlt bei zu groben Daten schnell die Aussagekraft.
- Zu viele oder zu flache Dimensionen - Ohne klare Hierarchie wird Drill-down zum Klick-Labyrinth.
- Langsam veränderliche Dimensionen - Das sind Dimensionen, deren Attribute sich über die Zeit ändern, etwa Kundenadresse oder Produktkategorie; historisch muss dann klar sein, welche Version gilt.
- Schwache Datenqualität - Dubletten, Lücken und widersprüchliche Stammdaten werden im Analysemodell nur sichtbarer, nicht kleiner.
Mein pragmatischer Test lautet: Wenn ich eine Kennzahl nicht in einem Satz erklären kann, ist sie noch nicht modellreif. Und wenn eine Fachseite dieselbe Zahl anders lesen würde als die andere, ist das Modell zwar technisch vorhanden, aber fachlich noch nicht belastbar.
Aus diesen Erfahrungen lassen sich für aktuelle Datenplattformen einige sehr robuste Regeln ableiten.
Was ich aus OLAP für moderne Datenanalyse mitnehme
Für mich ist OLAP vor allem eine Disziplin der klaren Fragen. Es lohnt sich, wenn Nutzer regelmäßig dieselben Kennzahlen aus mehreren Perspektiven brauchen, wenn historische Vergleiche wichtig sind und wenn das Ergebnis interaktiv sein soll. Genau dann spielt das Modell seine Stärke aus: Es macht aus Rohdaten eine verlässliche Entscheidungssicht.
Weniger sinnvoll ist es dort, wo jede Einzelaktion sofort geschrieben werden muss oder wo das System extrem volatile Echtzeitvorgänge ohne analytische Verdichtung abbilden soll. In solchen Fällen braucht es eher eine saubere Trennung zwischen operativer Verarbeitung, Streaming und Analyse. Wer beides vermischt, bekommt am Ende meist nur ein System, das weder schnell genug transagiert noch angenehm auswertet.
Wenn ich eine moderne Datenplattform bewerte, achte ich deshalb zuerst auf die fachliche Modellierung, dann auf die Speicher- und Aggregationsstrategie und erst danach auf das Frontend. Genau diese Reihenfolge entscheidet am Ende darüber, ob die Analyse im Alltag wirklich trägt.