
Eine gute Datenbank ist mehr als ein Speicher für Tabellen. Ihr Aufbau entscheidet darüber, ob Daten sauber gepflegt, schnell gefunden und später sinnvoll ausgewertet werden können. Genau darum geht es hier: vom logischen Kern über Schlüssel und Indizes bis zu der Frage, warum Datenanalyse oft eine andere Struktur braucht als operative Systeme.
Die wichtigsten Punkte auf einen Blick
- Eine Datenbank besteht nicht nur aus Tabellen, sondern auch aus Schemas, Beziehungen, Regeln und Metadaten.
- Primärschlüssel und Fremdschlüssel sorgen dafür, dass Datensätze eindeutig bleiben und logisch zusammenhängen.
- Indizes beschleunigen Abfragen, können aber Schreibvorgänge und Wartung verlangsamen, wenn man sie übertreibt.
- Für Analysezwecke wird Daten oft anders modelliert als für operative Prozesse mit vielen Einzeltransaktionen.
- NoSQL ist keine universell bessere Lösung, sondern passt zu anderen Zugriffsmustern und Datenformen.
Was eine Datenbank im Kern ausmacht
Ich denke beim Datenbankaufbau immer in zwei Ebenen: logisch und physisch. Logisch geht es darum, welche Informationen überhaupt gespeichert werden, wie sie zusammenhängen und welche Regeln gelten. Physisch geht es darum, wie das System die Daten tatsächlich ablegt, beschleunigt und absichert. Eine einzelne Tabelle ist also nur ein Teil des Ganzen, nicht die ganze Antwort.
In relationalen Systemen spielt das Schema eine zentrale Rolle. Ein Schema ist ein logischer Namensraum innerhalb einer Datenbank, in dem Tabellen, Views, Funktionen und weitere Objekte organisiert werden. Das ist praktisch, weil sich so Fachbereiche trennen lassen, ohne dass die Struktur chaotisch wird. Für mich ist das der Punkt, an dem aus bloßer Speicherung ein sauber gebautes System wird.
Auch die Metadaten gehören zum Aufbau. Sie beschreiben Daten über Daten, also etwa Spaltennamen, Datentypen, Rechte oder Beziehungen. Ohne Metadaten weiß das DBMS nicht, ob eine Spalte ein Datum, eine Zahl oder ein Textfeld ist. Genau diese zusätzliche Ebene macht Datenbanken so viel robuster als einfache Dateisammlungen. Damit stehen die Grundbausteine, und der Blick auf die einzelnen Komponenten lohnt sich jetzt umso mehr.
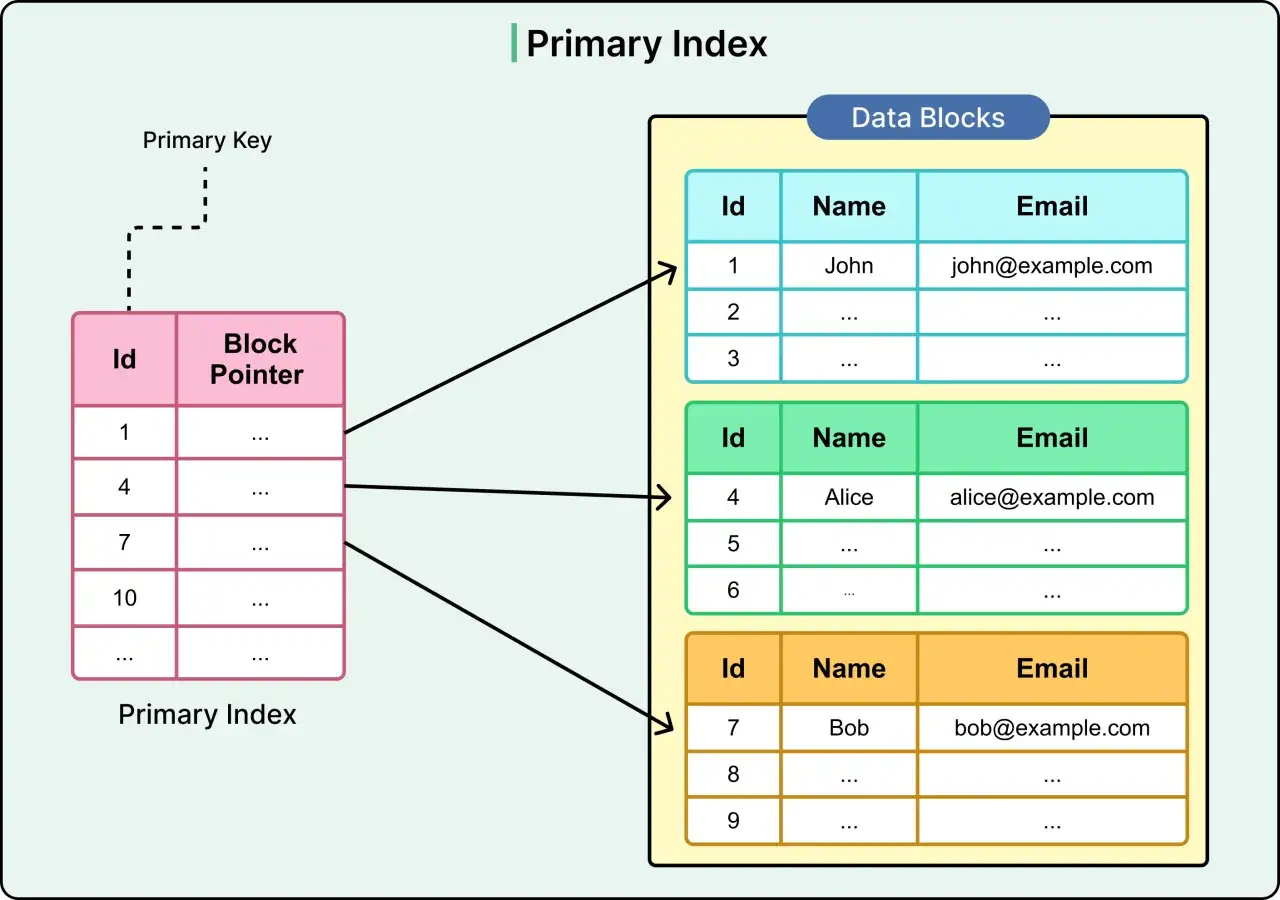
Die zentralen Bausteine einer relationalen Datenbank
Wenn ich eine relationale Datenbank auseinandernehme, landen wir fast immer bei denselben Bausteinen. Sie wirken unspektakulär, entscheiden aber darüber, ob das System später sauber wächst oder schnell unübersichtlich wird.
| Baustein | Aufgabe | Praktischer Effekt |
|---|---|---|
| Tabelle | Hält Daten zu einem klaren Thema, etwa Kunden, Bestellungen oder Messwerte. | Macht die Struktur verständlich und fachlich trennbar. |
| Spalte | Beschreibt ein einzelnes Merkmal wie Name, Datum, Preis oder Status. | Sorgt für einheitliche Datentypen und gute Abfragen. |
| Datensatz | Entspricht einer Zeile mit zusammengehörigen Werten. | Repräsentiert ein konkretes Objekt oder Ereignis. |
| Primärschlüssel | Identifiziert jeden Datensatz eindeutig. | Verhindert Dubletten und schafft eine stabile Referenz. |
| Fremdschlüssel | Verweist auf einen Datensatz in einer anderen Tabelle. | Verbindet Tabellen logisch miteinander. |
| Constraint | Erzwingt Regeln wie NOT NULL, UNIQUE oder Wertebereiche. | Erhöht Datenqualität und verhindert fehlerhafte Einträge. |
| Index | Beschleunigt den Zugriff auf bestimmte Spalten oder Ausdrücke. | Verbessert Lesegeschwindigkeit, kostet aber Speicher und Pflegeaufwand. |
| Datentyp | Legt fest, ob ein Feld Text, Zahl, Datum oder booleschen Wert enthält. | Reduziert Fehler und macht Auswertungen berechenbarer. |
Besonders wichtig ist der Primärschlüssel. Ohne ihn wird es schwer, Datensätze eindeutig zu identifizieren, sauber zu verknüpfen oder Änderungen nachvollziehbar zu machen. Fremdschlüssel wiederum sorgen dafür, dass Beziehungen nicht nur auf dem Papier existieren, sondern technisch erzwungen werden. Ich halte das für einen der größten Unterschiede zwischen gut modellierten und bloß irgendwie gefüllten Datenbeständen.
Auch der Index wird oft missverstanden. Ein Index ist keine magische Beschleunigung für alles, sondern eine gezielte Zugriffshilfe. Bei Suchabfragen auf häufig genutzten Spalten kann er viel bringen, bei ungeeigneten Mustern aber auch unnötig bremsen. Genau deshalb gehört zu einem sauberen Aufbau immer die Frage: Welche Abfragen sind später wirklich wichtig? Von dort aus wird die Modellierung erst richtig sinnvoll.
Wie Beziehungen und Normalisierung Daten sauber halten
Sobald mehrere Tabellen zusammenarbeiten, wird die Modellierung interessant. Beziehungen sind das Rückgrat relationaler Datenbanken, weil sie Daten logisch verbinden, ohne sie ständig zu duplizieren. Typische Formen sind 1:1, 1:n und n:m. In der Praxis begegnet man vor allem 1:n-Verbindungen, etwa ein Kunde zu vielen Bestellungen.
Eine n:m-Beziehung braucht fast immer eine Zwischentabelle. Ein Kunde kann mehrere Produkte kaufen, und ein Produkt kann in vielen Bestellungen vorkommen. Statt diese Beziehung unübersichtlich in einer einzigen Tabelle abzubilden, legt man häufig eine Bestellpositionstabelle an. Das ist nicht nur ordentlicher, sondern später auch analytisch leichter auszuwerten.
Hier kommt die Normalisierung ins Spiel. Sie reduziert Redundanz, indem Informationen so verteilt werden, dass ein Fakt möglichst nur an einer Stelle gepflegt wird. Das verhindert Widersprüche wie zwei unterschiedliche Adressen für denselben Kunden oder mehrfach gespeicherte Produktnamen mit kleinen Abweichungen. Für operative Systeme ist das oft ein großer Gewinn, weil Schreibfehler und Inkonsistenzen seltener werden.
Ganz ohne Grenzen ist dieser Ansatz aber nicht. Zu starke Normalisierung kann Abfragen komplizierter machen, weil viele Tabellen über Joins zusammengeführt werden müssen. Für Analyse oder Reporting ist das nicht immer ideal. Ich würde es so formulieren: Normalisiere so weit, dass die Daten konsistent bleiben, aber nicht so weit, dass jede Auswertung zum Puzzle wird. Genau dort beginnt der Übergang zur Analyseperspektive.
Warum der Aufbau für Datenanalyse so wichtig ist
Bei Datenanalyse zählt nicht nur, dass Daten gespeichert sind, sondern wie sie gelesen werden. Operative Systeme, also OLTP-Datenbanken, sind auf viele kleine Schreib- und Lesevorgänge ausgelegt. Analytische Systeme, also OLAP-Modelle, müssen große Datenmengen oft aggregieren, filtern und vergleichen. Diese beiden Ziele verlangen unterschiedliche Strukturen.
| Kriterium | Operative Datenbank | Analytische Datenbank |
|---|---|---|
| Ziel | Schnelle Transaktionen und aktuelle Einzelvorgänge | Auswertungen, Trends und Aggregationen |
| Struktur | Oft stark normalisiert | Oft denormalisiert oder als Sternschema modelliert |
| Tabellentypen | Fachtabellen wie Kunden, Aufträge, Zahlungen | Fakt- und Dimensionstabellen |
| Abfrageprofil | Viele kleine Punktzugriffe | Wenige, aber große Scans und Gruppierungen |
| Optimierung | Indizes für präzise Zugriffe | Columnstore oder andere analytische Strukturen |
Das Sternschema ist in Analyseszenarien besonders verbreitet. Es besteht aus einer oder mehreren Faktentabellen, die messbare Ereignisse speichern, und Dimensionstabellen, die Kontext liefern, etwa Zeit, Produkt, Region oder Kundengruppe. Die Granularität ist hier entscheidend: Eine Zeile kann einen einzelnen Verkauf, einen Tageswert oder eine Zusammenfassung pro Region darstellen. Je klarer diese Ebene definiert ist, desto verlässlicher werden die Auswertungen.
Auch die Speicher- und Indexstrategie ändert sich. Ein Columnstore-Index legt Daten spaltenweise ab, was bei großen analytischen Abfragen oft Vorteile bringt, weil nur die wirklich benötigten Spalten gelesen werden. Ein klassischer B-Tree-Index ist dagegen meist stärker auf punktgenaue Suchen ausgelegt. Ich sehe in Projekten oft genau an dieser Stelle den ersten echten Qualitätssprung: Wenn das Datenmodell zum Analysefall passt, werden Dashboards schneller, Abfragen verständlicher und Wartungskosten geringer. Wer diese Unterscheidung verstanden hat, kann auch Datenbanktypen nüchterner bewerten.
Wann relationale Modelle reichen und wann NoSQL sinnvoller ist
Ich würde relationale Datenbanken nicht vorschnell gegen NoSQL ausspielen. Für Kundenstämme, Bestellungen, Rechnungen, Lagerdaten und viele Reporting-Szenarien sind relationale Modelle immer noch die vernünftigste Wahl. Sie liefern klare Regeln, gute Integrität und ein sehr etabliertes Werkzeugset.
| Modell | Stärken | Grenzen | Typische Einsatzfälle |
|---|---|---|---|
| Relational | Starke Integrität, Joins, gut für strukturierte Daten | Schemaänderungen brauchen Disziplin | Business-Daten, ERP, CRM, Reporting |
| Dokumentenorientiert | Flexible Struktur, gut für wechselnde Felder | Beziehungen und Konsistenz sind weniger strikt | Content, Produktkataloge, JSON-lastige Anwendungen |
| Key-Value | Sehr schnell für direkte Schlüsselzugriffe | Kaum komplexe Abfragen | Sessions, Caches, einfache Lookup-Daten |
| Graph | Stark bei Netzwerken und Pfaden | Für klassische Tabellenreports oft weniger bequem | Empfehlungen, soziale Beziehungen, Abhängigkeitsanalysen |
NoSQL ist also nicht automatisch moderner oder besser. Es löst andere Probleme. Wenn Daten stark verschachtelt, sehr variabel oder in hoher Geschwindigkeit ohne strenges Schemaskorsett verarbeitet werden müssen, kann ein alternatives Modell sinnvoll sein. Wenn dagegen Geschäftslogik, Konsistenz und Auswertung wichtig sind, bleibe ich meist bei relationalen Systemen oder kombiniere beide Welten bewusst. Die eigentliche Frage lautet nie: Was ist trendy?, sondern: Welches Zugriffsmuster dominiert?
Gerade bei modernen Architekturen sehe ich oft Mischformen. Ein System speichert operative Daten relational, übergibt aber Events oder JSON-Dokumente an Analyse- und Integrationsschichten. Das ist völlig legitim, solange die Übergänge sauber definiert sind. Problematisch wird es erst, wenn man alles in ein Modell pressen will und danach überrascht ist, dass weder Analyse noch Betrieb wirklich gut laufen. Genau deshalb lohnt sich ein Blick auf die häufigsten Entwurfsfehler.
Typische Fehler beim Datenbankaufbau
Die meisten Probleme entstehen nicht durch das Datenbanksystem selbst, sondern durch einen unklaren Entwurf. Ich sehe dabei immer wieder dieselben Stolpersteine.
- Kein klarer Primärschlüssel - Ohne eindeutige Identität werden Dubletten und Inkonsistenzen schnell zum Dauerproblem.
- Zu viele oder zu wenige Indizes - Beides schadet: zu wenig macht Abfragen langsam, zu viele bremsen Schreibvorgänge und erhöhen Wartungskosten.
- Unpassende Datentypen - Wenn fast alles als Text gespeichert wird, gehen Validierung, Performance und Lesbarkeit verloren.
- m:n-Beziehungen direkt in einer Tabelle - Das erzeugt Wiederholungen und macht spätere Auswertungen unnötig kompliziert.
- Analyse- und Operativdaten vermischen - Dann konkurrieren kleine Buchungen mit schweren Auswertungen, was beides verschlechtert.
- Keine Namenskonventionen - Ohne klare Regeln wird das Schema schnell schwer wartbar, vor allem im Team.
Auch bei der Wartbarkeit wird oft zu kurz gedacht. Eine Datenbank ist kein einmaliges Projekt, sondern ein lebendes System. Wer heute sauber modelliert, spart morgen Arbeit bei Erweiterungen, Migrationen und Auswertungen. Das ist kein theoretischer Luxus, sondern im Alltag meist der teuerste Unterschied zwischen solider und schlechter Architektur. Damit lässt sich der Blick auf die Praxis am Ende sehr konkret machen.
Woran ich eine gut aufgebaute Datenbank im Alltag erkenne
Wenn ich ein Modell schnell einschätzen will, prüfe ich nicht zuerst die Anzahl der Tabellen, sondern die Qualität der Struktur. Eine gut aufgebaute Datenbank ist für mich leicht verständlich, logisch verknüpft und an reale Zugriffe angepasst. Sie wirkt weder aufgebläht noch übermäßig vereinfacht.
- Jede zentrale Tabelle hat eine eindeutige Identität.
- Beziehungen sind über Fremdschlüssel oder klare Regeln nachvollziehbar.
- Wichtige Auswertungen lassen sich ohne unnötig lange Join-Ketten durchführen.
- Indizes sind begründet und an tatsächliche Abfragen gekoppelt.
- Schemata, Datentypen und Benennungen folgen einer erkennbaren Ordnung.
Am Ende ist der beste Aufbau der, der zum Zweck passt. Für operative Systeme brauche ich Konsistenz und klare Transaktionslogik, für Analyse brauche ich Struktur, die große Datenmengen schnell und verständlich nutzbar macht. Wenn beides zusammenspielt, wird eine Datenbank nicht nur technisch korrekt, sondern auch fachlich wirklich wertvoll. Genau daran messe ich jeden Entwurf: nicht an seiner Theorie, sondern daran, wie gut er im Alltag trägt.