
In einem Data Warehouse wird die Vergangenheit nur dann korrekt lesbar, wenn sich Stammdaten nicht einfach überschreiben. Genau dafür nutze ich historisierte Dimensionen: Sie trennen aktuelle Werte von früheren Zuständen und machen Zeitvergleiche, Audits und Ursachenanalysen belastbar. Die Methode der slowly changing dimensions ist deshalb nicht nur ein Modellierungstrick, sondern oft die Voraussetzung dafür, dass Berichte im Nachhinein noch fachlich stimmen.
Die Technik, die historische Analysen im Warehouse stabil macht
- Sie hält den aktuellen Zustand und frühere Versionen einer Dimension getrennt, damit Auswertungen zeitlich sauber bleiben.
- Für die Praxis sind vor allem Type 1, Type 2 und Type 3 relevant; ergänzend helfen temporale Tabellen oder separate Historientabellen.
- Surrogate Keys, Gültigkeitszeiträume und ein Current-Flag sind die typischen Bausteine für eine belastbare Umsetzung.
- Type 1 ist schnell und schlank, Type 2 liefert vollständige Historie, Type 3 nur eine begrenzte Rückschau.
- Moderne Plattformen setzen häufig auf Snapshots, CDC oder system-versionierte Tabellen statt auf handgeschriebene Update-Logik.
Was historisierte Dimensionen im Warehouse wirklich leisten
Die meisten Dimensionen - Kunde, Produkt, Region, Mitarbeiter, Tarif - ändern sich selten. Aber wenn sie sich ändern, hat das oft direkte Folgen für Auswertungen. Wird ein Vertriebsmitarbeiter rückwirkend in eine andere Region verschoben, verfälscht ein bloß überschriebenes Attribut alte Umsatzberichte. Genau hier liegt der eigentliche Nutzen: Ich kann mit einer historisierten Dimension beantworten, wie das System zu einem bestimmten Zeitpunkt aussah.
Das ist für Monatsabschlüsse, regulatorische Nachweise und punktgenaue Trendanalysen oft wichtiger als der perfekte aktuelle Stand. Wer diese Trennung nicht sauber zieht, baut Berichte, die heute richtig wirken und morgen still falsch werden. Aus meiner Sicht ist das einer der häufigsten Denkfehler in der Datenmodellierung: Der aktuelle Zustand wird mit der historischen Wahrheit verwechselt.
Als Nächstes stellt sich deshalb nicht die Frage, ob Historie sinnvoll ist, sondern wie viel Historie das Modell tatsächlich braucht. Genau daran entscheidet sich die passende Variante.
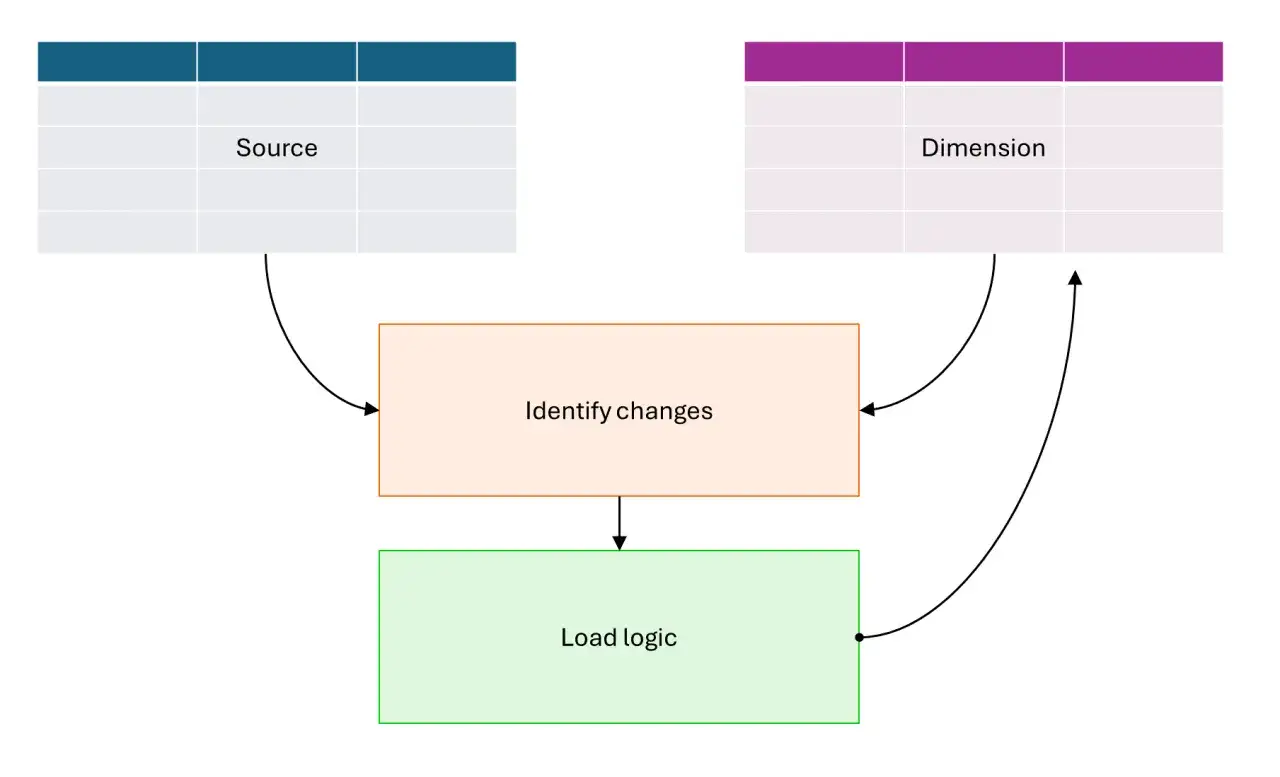
Welche Variante zu welchem Datenproblem passt
In der Praxis reichen meist vier Muster. Ich halte Type 1 für Korrekturen, Type 2 für echte Historie, Type 3 für eine begrenzte Rückschau und temporale Tabellen oder separate Historientabellen für Plattformen, die Historie nativ unterstützen.
| Variante | Was passiert | Stärken | Schwächen | Typischer Einsatz |
|---|---|---|---|---|
| Type 1 | Alte Werte werden überschrieben | Einfach, schnell, wenig Speicher | Keine Historie, alte Analysen können sich ändern | Korrekturen, Kontaktfelder, unkritische Stammdaten |
| Type 2 | Jede Änderung erzeugt eine neue Version | Vollständige Historie, saubere Point-in-time-Analysen | Mehr Zeilen, mehr Lade- und Join-Logik | Region, Status, Zuordnung, Compliance, Audit |
| Type 3 | Vorherige Werte landen in zusätzlichen Spalten | Direkter Vorher-nachher-Vergleich | Nur begrenzte Historie, schnell unübersichtlich | Wenn nur eine frühere Sicht zusätzlich nötig ist |
| Type 4 / getrennte Historie | Aktueller Stand und Historie liegen getrennt | Saubere Trennung, oft gut mit DB-Funktionen kombinierbar | Mehr Tabellen und mehr Abstimmung im Modell | Temporale Tabellen, Plattformen mit eingebauter Historisierung |
Wenn ich zwischen den Varianten entscheiden muss, frage ich immer zuerst: Braucht das Fachteam nur den aktuellen Stand oder auch die Version, die zum Zeitpunkt eines Ereignisses gültig war? Sobald die Antwort auf Letzteres lautet, führt Type 1 praktisch nicht mehr weit genug. Dann wird die Modellfrage plötzlich sehr konkret: Welche Schlüssel, welche Zeitachsen und welche Version sollen später im Fact-Join hängen?
Damit ist die Auswahl getroffen, aber das eigentliche Modell ist noch nicht sauber gebaut. Genau dort liegen die Details, die über Belastbarkeit oder spätere Korrekturen entscheiden.
So sieht ein robustes Dimensionsmodell aus
Ein brauchbares Modell steht und fällt mit vier Dingen: Geschäftsschlüssel, Surrogate Key, Gültigkeitsfenster und Current-Flag. Wenn diese Bausteine nicht sauber zusammenspielen, wird jede Änderung im Nachhinein teuer.
Naturliche Schlüssel und Surrogate Keys trennen
Der natürliche Schlüssel kommt aus dem Quellsystem, zum Beispiel Kundennummer, Produktcode oder Mitarbeiter-ID. Der Surrogate Key wird im Warehouse erzeugt und identifiziert nicht die Geschäftseinheit, sondern eine konkrete Version dieser Einheit. Genau deshalb referenzieren Fact-Tabellen in einer Type-2-Struktur nicht die Kundennummer allein, sondern die Version, die zum Buchungszeitpunkt gültig war.
Gültigkeit statt Überschreiben modellieren
Ich arbeite fast immer mit valid_from und valid_to oder mit StartDate und EndDate. Ein offener Endwert wie 9999-12-31 oder ein NULL-Ende markiert die aktuelle Zeile sehr klar. Ergänzend setze ich oft ein IsCurrent-Flag ein, weil BI-Modelle und ETL-Jobs damit ohne komplizierte Datumslogik erkennen, welche Version gerade aktiv ist.
Lesen Sie auch: SQL vor Datum filtern - So gelingt der präzise Vergleich
Nur historisieren, was fachlich zählt
Nicht jedes Feld verdient Type 2. E-Mail-Adresse, Telefonnummer oder eine bloße Rechtschreibkorrektur sind oft Type 1, weil nur der aktuelle Stand relevant ist. Region, Segment oder Vertragsstatus dagegen sind häufig historisch relevant, weil sie alte Fakten anders interpretierbar machen. Wenn ein Attribut extrem häufig wechselt, prüfe ich zuerst, ob es besser in die Fact-Tabelle oder in eine separate, feinere Dimension gehört. Gerade bei sehr beweglichen Werten ist Type 2 schnell teurer, als es der fachliche Nutzen rechtfertigt.
Sobald das Schema steht, kommt der Ladeprozess. Und genau dort passieren die meisten logischen Fehler, weil Vergleich, Versionierung und Faktenbezug zusammenlaufen.
Wie die Verarbeitung in SQL oder ETL sauber abläuft
Der Ladeprozess für Type 2 ist eigentlich simpel, aber nur, wenn die Vergleichslogik sauber definiert ist. Ich gehe immer von einer klaren Reihenfolge aus: erkennen, schließen, einfügen, verknüpfen.
- Quelle lesen und Schlüssel normalisieren Ich gleiche Schreibweisen, Datentypen und fachliche Schlüssel an, bevor ich überhaupt Änderungen bewerte. Schon kleine Inkonsistenzen erzeugen sonst falsche Deltas.
- Änderungen identifizieren Das passiert oft über einen Hash über relevante Attribute oder über einen Feldvergleich. Ein Hash ist praktisch, wenn viele Spalten beteiligt sind und der Vergleich effizient bleiben soll.
- Alte Version beenden Die aktuelle Zeile bekommt ein Enddatum und wird als nicht mehr aktuell markiert. Die historische Zeile bleibt erhalten, damit alte Fakten weiterhin auf die damals gültige Version zeigen.
- Neue Version einfügen Die neue Zeile erhält einen neuen Surrogate Key, ein neues Startdatum und den aktuellen Wert der Attribute. So entsteht die nächste Version derselben Geschäftseinheit.
- Fakten zum richtigen Stichtag auflösen Beim Join darf nicht einfach die letzte Zeile genommen werden. Entscheidend ist, welche Version zum fachlichen Ereignisdatum gültig war.
Der Punkt, den viele Teams unterschätzen: Das fachliche Ereignisdatum und das technische Ladedatum sind nicht dasselbe. Wenn ein Kunde seine Adresse am 3. März ändert, die Daten aber erst am 5. März geladen werden, muss klar sein, welches Datum für die historische Wahrheit zählt. In analytischen Systemen ist das fast immer das fachliche Datum, nicht der Zeitpunkt des Imports.
In stabilen Pipelines ist der technische Weg deshalb oft weniger wichtig als die Disziplin bei den Regeln. Wer das sauber trennt, verhindert später Diskussionen darüber, warum ein Bericht gestern noch anders aussah.
Wo Projekte mit SCD am häufigsten scheitern
Ich sehe in Projekten immer wieder dieselben Fehler. Sie sind nicht spektakulär, aber sie verursachen die teuersten Nacharbeiten, weil sie erst spät auffallen.
- Geschäftsschlüssel und Versionsschlüssel werden verwechselt Die Kundennummer bleibt gleich, aber die historische Version braucht einen eigenen Surrogate Key. Wer das vermischt, zerstört saubere Joins.
- Zu viele Attribute werden historisiert Wenn jede Kleinigkeit Type 2 wird, wächst die Dimension unnötig stark. Nicht alles, was sich ändert, ist analytisch relevant.
- Gültigkeitsintervalle überlappen sich Das passiert oft bei fehlerhaften Updates oder parallelen Läufen. Dann ist nicht mehr eindeutig, welche Version zu einem Datum gehört.
- Löschungen werden ignoriert Eine Quelle kann Datensätze entfernen, aber das Warehouse muss fachlich entscheiden, ob die letzte Version ausläuft, gesperrt wird oder aus Aufbewahrungsgründen bleibt.
- DSGVO und Aufbewahrung werden erst am Ende bedacht Historie ist kein Freifahrtschein für unbegrenzte Speicherung. Gerade bei personenbezogenen Daten braucht die Historisierung ein Lösch- und Retentionskonzept.
Mein pragmatischer Rat ist einfach: Nur die Attribute historisieren, die für spätere Fragen wirklich gebraucht werden, und die Regeln vor dem ersten Produktivlauf schriftlich festhalten. Sonst wird aus einem klaren Modell schnell eine Sammlung von Sonderfällen. Genau deshalb lohnt sich heute der Blick auf moderne Plattformen und die Frage, wie viel davon bereits vom Stack übernommen werden kann.
Was 2026 in modernen Plattformen am besten funktioniert
Heute würde ich solche Modelle selten komplett von Hand bauen, wenn die Plattform passende Bausteine mitbringt. In der Praxis sehe ich drei funktionierende Wege, die sich oft sogar kombinieren lassen: Snapshots, CDC und temporale Tabellen.
- Snapshots Sinnvoll, wenn die Quelle nur Zustände liefert und keine sauberen Änderungsereignisse ausgibt. Für Type 2 ist das robust, solange die Snapshot-Logik konsistent geplant wird.
- CDC Wenn das Quellsystem Änderungen als Change Feed oder Log-Extrakt bereitstellt, ist das meist der sauberste Weg. Änderungen werden dann inkrementell verarbeitet, statt immer komplette Tabellen zu vergleichen.
- Temporale Tabellen Gut, wenn die Datenbank Historie nativ verwaltet. Das reduziert eigene Update-Logik, ersetzt aber nicht automatisch die fachliche Modellierung für Berichte.
- Time travel Nützlich für Debugging und technische Rückfragen, aber kein Ersatz für eine fachlich gültige Versionierung. Eine zurückrollbare Tabelle ist noch keine analytisch saubere Dimension.
Wenn ich die Architektur heute neu entwerfe, trenne ich meist drei Ebenen: Rohdaten mit Änderungslogik, historisierte Dimension im Warehouse und ein semantisches Modell für den Konsum. So bleibt die Historie dort, wo sie hingehört, und die BI-Schicht wird nicht mit technischer Komplexität überladen. Das ist meistens weniger glamourös als eine einzige Superlösung, aber im Betrieb deutlich verlässlicher.
Die beste Umsetzung ist nicht die mit den meisten Features, sondern die, die sich klar testen, nachvollziehen und langfristig pflegen lässt. Genau dort zeigt sich, ob ein Warehouse die Vergangenheit wirklich beherrscht oder nur den letzten Stand speichert.
Welche Entscheidung ich in neuen Projekten zuerst festlege
Wenn ich ein neues Warehouse aufsetze, entscheide ich zuerst drei Dinge: Welche Attribute sind nur aktuell relevant? Welche Felder müssen historisch auswertbar bleiben? Und welcher Stichtag gilt fachlich - Änderungsdatum, Buchungsdatum oder Ladedatum? Erst wenn diese Fragen sauber beantwortet sind, lohnt sich die Modellierung im Detail.
Als Faustregel funktioniert Type 1 für Korrekturen und unkritische Kontaktfelder, Type 2 für echte Zeitachsen und Type 3 nur dort, wo ein direkter Vorher-nachher-Vergleich genügt. Wer diese Grenze früh festlegt, spart sich später teure Umbauten, widersprüchliche Berichte und Diskussionen über die „richtige“ Vergangenheit.
In der Praxis ist das die eigentliche Stärke historisierter Dimensionen: Sie machen Daten nicht nur speicherbar, sondern analytisch belastbar. Wenn du das Modell am Anfang konsequent auf die fachliche Frage ausrichtest, wird aus einem gewöhnlichen Warehouse ein verlässliches Instrument für Zeitvergleiche, Audits und Entscheidungen.