
Ein Star-Schema, also ein star schema im engeren Sinn, ordnet analytische Daten so, dass Berichte schnell, verständlich und belastbar bleiben. Statt alles in einer großen Tabelle zu mischen, trennt das Modell Fakten von beschreibendem Kontext und macht Auswertungen in Data-Warehouse-Umgebungen deutlich einfacher. In diesem Artikel zeige ich, wie die Struktur funktioniert, wann sie sich lohnt, wo ihre Grenzen liegen und welche Designfehler ich in Projekten immer wieder sehe.
Die wichtigsten Punkte auf einen Blick
- Faktentabellen speichern Ereignisse und Kennzahlen, Dimensionstabellen liefern den fachlichen Kontext.
- Der fachliche Grain muss vor dem Laden klar sein, sonst werden Summen und Vergleiche später unzuverlässig.
- Für Reporting, OLAP und Self-Service-Analytics ist das Modell meist leichter nutzbar als ein stark normalisiertes OLTP-Schema.
- Eine Schneeflocke lohnt sich eher bei tiefen Hierarchien oder wenn Redundanz bewusst reduziert werden soll.
- Die häufigsten Fehler sind gemischte Granularität, fehlende Datumstabelle und unnötige Many-to-many-Beziehungen.
Was ein Sternschema analytischen Teams bringt
Ich sehe das Sternschema als Übersetzungsmodell zwischen Fachbereich und Datenbank. Die Fachseite fragt selten nach Tabellenbeziehungen, sondern nach Umsatz, Menge, Bestandsverlauf oder Conversion pro Region. Genau dafür ist diese Struktur gebaut: Sie macht Kennzahlen aggregierbar und Kontextdaten filterbar, ohne dass jede Abfrage zur Join-Konstruktion wird.
Microsoft Learn betont dabei klar die Rollenverteilung: Dimensionstabellen liefern Filter und Gruppierung, Faktentabellen tragen Summen und Messwerte. AWS weist ergänzend darauf hin, dass Data Warehouses dafür meist denormalisierte Schemata nutzen, während OLTP-Datenbanken auf hohe Transaktionslast optimiert sind. Diese Trennung ist kein akademisches Detail, sondern der Grund, warum Analysen in Warehouses anders modelliert werden als operative Systeme.Wichtig ist auch die Perspektive auf die Lesbarkeit. Ein gut gebautes Sternschema ist für Analysten und BI-Entwickler meist intuitiv: In der Mitte steht die Faktentabelle, außen herum liegen die Dimensionen. Genau diese Trennung entscheidet später, wie leicht sich das Modell lesen und abfragen lässt.
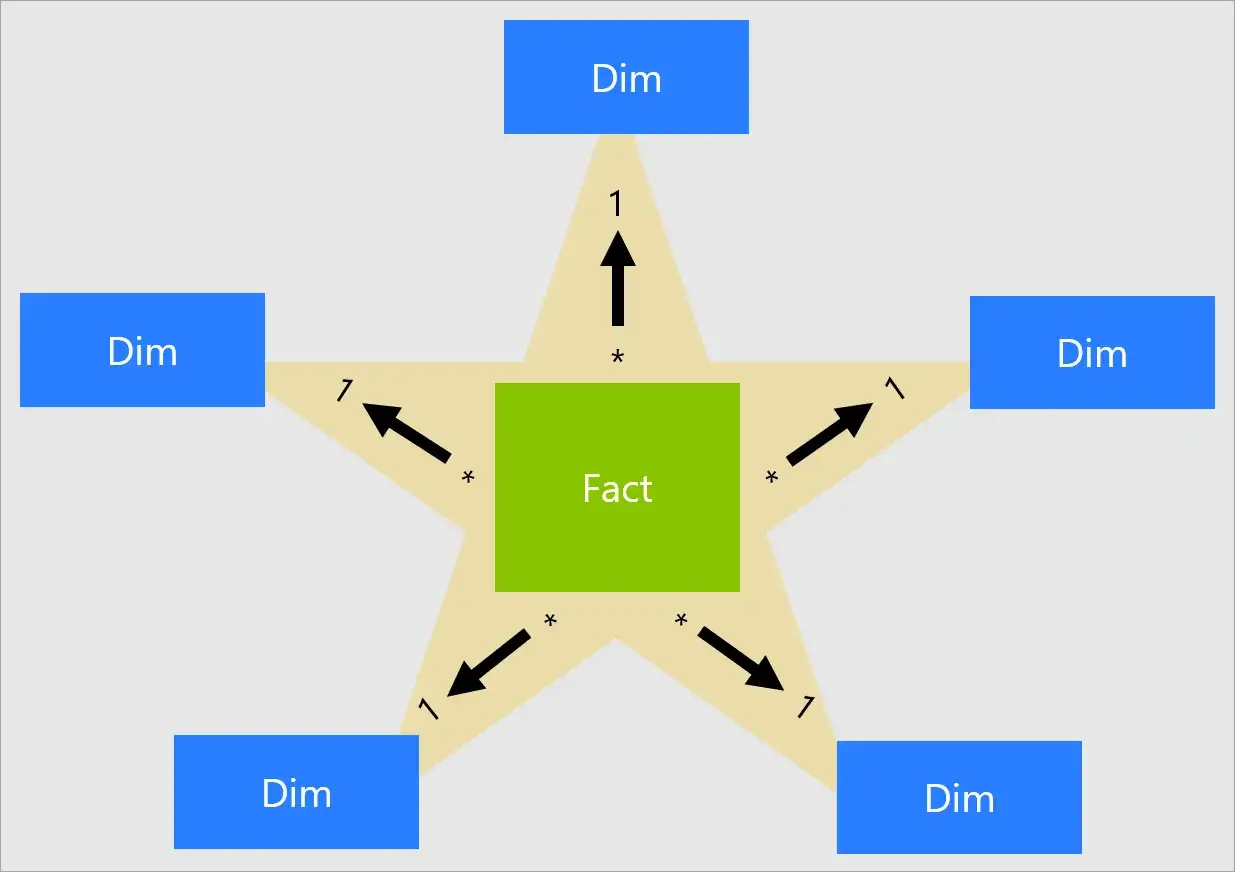
Wie Fakt- und Dimensionstabellen zusammenspielen
Das Modell wird erst verständlich, wenn man die beiden Hauptrollen sauber trennt. Die Faktentabelle enthält Ereignisse oder Zustände, die sich messen lassen, etwa Verkäufe, Klicks, Lagerbestände oder Zahlungsbuchungen. Dimensionstabellen liefern die beschreibenden Merkmale dazu, also zum Beispiel Produkt, Kunde, Zeit, Standort oder Vertriebskanal.
| Baustein | Aufgabe | Typische Inhalte |
|---|---|---|
| Faktentabelle | Speichert messbare Ereignisse und die Fremdschlüssel zu den Dimensionen | Umsatz, Menge, Dauer, Bestände, Klicks |
| Dimensionstabelle | Beschreibt das fachliche Umfeld und ermöglicht Filterung | Produktname, Kategorie, Kunde, Region, Datum |
| Grain | Definiert die fachliche Auflösung einer Zeile | Eine Bestellung, eine Position, ein Tag pro Produkt, ein Ereignis |
| Kennzahl | Wird aggregiert, gefiltert oder verglichen | Umsatzsumme, Stückzahl, Marge, Verweildauer |
Der entscheidende Punkt ist der Grain, also die kleinste fachliche Auflösung. Eine Zeile kann eine einzelne Bestellposition bedeuten, einen Tagesstand pro Produkt oder ein Ereignis pro Nutzer und Zeitstempel. Wenn dieser Zuschnitt unklar ist, wirken die Daten am Anfang oft plausibel, kippen aber bei den ersten echten Fachfragen.
Dimensionstabellen sind dagegen meist stabiler und deutlich kleiner. Sie enthalten Attribute, die selten jede Nacht neu erfunden werden müssen, aber häufig zum Filtern gebraucht werden. Produktkategorie, Kundengruppe oder Kalenderwoche sind klassische Beispiele, weil sie den Daten erst den analytischen Sinn geben.
Genau diese Aufteilung macht den praktischen Wert des Modells aus: Die Faktentabelle bleibt schlank und wächst stark, die Dimensionen liefern den Kontext. Von hier aus ist der Schritt zur passenden Einsatzsituation nicht mehr groß.
Wann ich dieses Modell einsetze und wann nicht
Ich setze ein Sternschema ein, wenn Fachanwender regelmäßig nach Zeit, Produkt, Kunde, Region oder Kanal auswerten und die Antwort schnell, nachvollziehbar und konsistent sein muss. Das ist typisch für Reporting, Controlling, Vertriebsauswertungen, Marketing-Analysen und viele Self-Service-BI-Szenarien. Je klarer die Geschäftsfragen sind, desto stärker spielt das Modell seine Stärke aus.
Besonders gut passt es, wenn die Datenhistorie wichtig ist. Analysen über Monate oder Jahre brauchen stabile Dimensionen und eine saubere Zeitleiste. Wenn ich beispielsweise Umsätze pro Produktlinie, Filiale und Monat untersuchen will, ist das Modell meist schneller und verständlicher als ein tief verschachteltes, stark normalisiertes Schema.
Weniger geeignet ist es, wenn du noch mitten in der operativen Systemlogik steckst oder die fachlichen Begriffe ständig wechseln. Dann lohnt sich meist zuerst eine saubere Staging- und Integrationsschicht. Erst danach sollte das analytische Modell gebaut werden, sonst modellierst du Unsicherheit statt Wahrheit.
Die Grenze liegt also nicht bei der Datenmenge, sondern bei der Stabilität des Fachmodells. Wenn die Begriffe und Kennzahlen klar sind, passt das Sternschema sehr gut; wenn nicht, brauchst du zuerst Ordnung im Quellsystem und in der fachlichen Definition.
So baue ich ein belastbares Modell auf
Den Grain zuerst festlegen
Ich beginne nie mit Tabellen, sondern mit einer einzigen Frage: Worum geht genau eine Zeile? Eine Bestellung, eine Position, ein Tag, ein Sensorwert oder ein Nutzerereignis? Erst wenn diese Antwort sauber formuliert ist, kann ich entscheiden, welche Kennzahlen in die Faktentabelle gehören und welche Dimensionen überhaupt sinnvoll sind.
Dimensionen bewusst schneiden
Eine gute Dimension beschreibt ein fachliches Objekt so, dass es sich filtern und gruppieren lässt. Produkt, Kunde, Region, Mitarbeiter, Datum oder Kampagne sind typische Kandidaten. Ich halte beschreibende Attribute dort, statt sie in die Faktentabelle zu schieben, weil das Modell sonst unnötig schwer und fachlich unsauber wird.
Historisierung kontrolliert lösen
Bei Änderungen an Stammdaten reicht Überschreiben oft nicht. Eine Type-1-Strategie ersetzt den alten Wert, eine Type-2-Strategie schreibt eine neue Zeile und bewahrt die Historie. Für Analysen mit Zeitbezug ist das oft entscheidend, etwa wenn ein Kunde umzieht, ein Produkt umklassifiziert wird oder ein Vertriebsgebiet neu zugeschnitten wird.
Lesen Sie auch: Dask vs. Spark - Welche Big-Data-Plattform ist die richtige?
Mehrfachrollen und Sonderfälle sauber abbilden
Eine Datumstabelle kann an derselben Faktentabelle mehrfach hängen, zum Beispiel für Bestell-, Versand- und Lieferdatum. Das ist kein Problem, solange die Rollen eindeutig benannt sind. Schwieriger wird es bei mehrwertigen Merkmalen, etwa mehreren Diagnosen, mehreren Verantwortlichen oder mehreren beteiligten Organisationen. Dann braucht es oft eine Brückentabelle, statt die Komplexität direkt in die Faktentabelle zu drücken.
Wenn diese vier Punkte sitzen, steht das Modell auf einem stabilen Fundament. Erst danach lohnt sich der Vergleich mit anderen Schemata.
Star-Schema oder Schneeflocke
Die häufigste Alternative ist die Schneeflocke. Sie normalisiert Dimensionen stärker, indem Hierarchien in zusätzliche Tabellen ausgelagert werden. Das kann sauber wirken, bringt aber meist mehr Joins und damit mehr Abfragekomplexität mit sich.
| Kriterium | Sternschema | Schneeflocke |
|---|---|---|
| Abfrageaufwand | Weniger Joins, meist direkter zu lesen | Mehr Joins, dafür feiner strukturiert |
| Verständlichkeit | Sehr hoch für BI und Self-Service | Höherer Einarbeitungsaufwand |
| Redundanz | Etwas höher, weil Dimensionen breiter sind | Geringer, weil Attribute verteilt werden |
| Wartung | Einfacher für Reporting-Teams | Präziser bei komplexen Hierarchien |
| Typischer Einsatz | Dashboards, Analyse, Self-Service-BI | Tief geschachtelte Domänen, strenge Normalisierung |
Ich nehme den etwas höheren Speicherverbrauch des Sternschemas meist in Kauf, weil die Verständlichkeit im Alltag wichtiger ist als theoretische Eleganz. Wenn Benutzer ohne Datenbankwissen mit dem Modell arbeiten sollen, gewinnt fast immer die einfachere Struktur. Eine Schneeflocke wird dann interessant, wenn Hierarchien sehr tief sind oder wenn die Pflege redundanter Attribute wirklich zum Problem wird.
Die gute Nachricht: Es gibt nicht die eine richtige Antwort. Die Modellwahl hängt davon ab, ob Lesbarkeit, Abfragegeschwindigkeit, Datenpflege oder Normalisierung im konkreten Projekt den größten Wert hat.
Typische Fehler, die Analysen ausbremsen
- Unklarer Grain - Wenn nicht feststeht, was eine Zeile repräsentiert, entstehen doppelte Summen oder scheinbar widersprüchliche Kennzahlen.
- Fakten und Attribute mischen - Beschreibende Texte in der Faktentabelle machen das Modell unnötig breit und schwer wartbar.
- Operative Struktur 1:1 übernehmen - Ein Quellsystem ist fast nie schon analytisch sinnvoll geschnitten.
- Viele Many-to-many-Beziehungen - Sie erhöhen die Komplexität und machen Filterpfade schnell unübersichtlich.
- Datumstabelle vergessen - Ohne saubere Zeitdimension werden Zeitreihenanalysen und Kalenderlogik unnötig fehleranfällig.
- Historie versehentlich überschreiben - Gerade bei Kunden-, Produkt- oder Organisationsdaten zerstört das rückwirkende Auswertungen.
Am Ende sind es oft keine spektakulären Designfehler, sondern kleine Nachlässigkeiten, die später teuer werden. In der Praxis sehe ich am häufigsten unklare Granularität und zu frühes Vermischen von Rohdaten mit Analysemodellen. Genau deshalb lohnt sich ein strenger Modellierungscheck, bevor das erste Dashboard produktiv geht.
Aus diesen Fehlern leite ich in Projekten klare Prüfpunkte ab, bevor ich Berichte freigebe. Das spart später viel Nacharbeit, gerade wenn mehrere Teams auf dieselbe Datenbasis zugreifen.
Welche Entscheidungen ich im Projekt sofort absichere
Wenn ich ein neues Analysemodell aufsetze, sichere ich zuerst drei Dinge: den Grain, die Schlüsselstrategie und die Historisierung. Danach prüfe ich, welche Dimensionen wirklich fachlich relevant sind und welche nur aus Gewohnheit mitgeschleppt würden. So bleibt das Modell schlank genug für schnelle Abfragen und gleichzeitig stabil genug für spätere Erweiterungen.
Für mich ist das der praktische Kern eines guten Sternschemas: nicht möglichst viele Tabellen, sondern die richtige Trennung von Messung und Kontext. Wer das sauber umsetzt, baut keine hübsche Diagrammfläche, sondern eine belastbare Grundlage für Reporting, Controlling und Ad-hoc-Analysen. Genau daran zeigt sich am Ende, ob ein Datenmodell im Alltag trägt.