
Eine tragfähige data pipeline architecture entscheidet darüber, ob Analysen verlässlich, aktuell und nachvollziehbar sind oder ob Teams später in manuellen Korrekturen versinken. Ich zeige hier, wie man den Aufbau von der Quelle bis zur Auswertung sauber denkt, welche Rolle ETL, ELT und Streaming spielen und warum Datenbankdesign, Governance und Monitoring die eigentliche Stabilität liefern. Wer mit Datenanalyse, Reporting oder modernen Datenbanken arbeitet, bekommt damit eine praktische Orientierung statt einer bloßen Begriffserklärung.
Die wichtigsten Punkte auf einen Blick
- Eine gute Pipeline bewegt Daten nicht nur, sondern macht sie analysierbar, prüfbar und belastbar.
- ETL, ELT und Streaming lösen unterschiedliche Probleme; die richtige Wahl hängt vor allem von Latenz und Zielsystem ab.
- Für analytische Daten sind klare Schichten wie Rohdaten, geprüfte Daten und Business-Daten meist sinnvoller als ein einziger großer Datenpool.
- Qualität, Lineage und Monitoring verhindern, dass fehlerhafte Werte unbemerkt in Dashboards und Berichte wandern.
- Die beste Architektur ist nicht die modernste, sondern die, die zu Datenvolumen, Teamgröße, Aktualitätsbedarf und Kosten passt.
Was eine belastbare Pipeline wirklich leisten muss
Ich betrachte eine Datenpipeline nie nur als Transportweg zwischen zwei Systemen. Sie ist die technische Antwort auf eine fachliche Frage: Wie kommen aus operativen Rohdaten zuverlässige Datenbestände, auf deren Basis ich Entscheidungen treffen kann? Genau daran misst sich die Qualität der Architektur, nicht an der Zahl der verwendeten Tools.
Damit eine Pipeline im Alltag trägt, muss sie vier Dinge gleichzeitig beherrschen: Aktualität, Nachvollziehbarkeit, Qualität und Kostenkontrolle. Fehlt einer dieser Punkte, rächt sich das später fast immer in Form von verspäteten Reports, unklaren Fehlerursachen oder unnötig teurer Infrastruktur.
- Nachvollziehbarkeit heißt: Ich kann erkennen, woher ein Wert kommt und wie er verändert wurde.
- Aktualität heißt: Die Daten sind so frisch, wie der Anwendungsfall es verlangt, nicht frischer.
- Qualität heißt: offensichtliche Fehler, Dubletten und Schemaabweichungen werden früh abgefangen.
- Kostenkontrolle heißt: Die Architektur passt zur tatsächlichen Nutzung und skaliert nicht blind auf Verdacht.
Ein Begriff, der hier oft fällt, ist idempotent. Das bedeutet einfach, dass ich einen Verarbeitungsschritt mehrfach ausführen kann, ohne doppelte oder verfälschte Ergebnisse zu erzeugen. Für Datenbanken und analytische Systeme ist das zentral, weil Wiederholungen bei Fehlern oder Neustarts sonst sofort zu inkonsistenten Tabellen führen. Von hier aus ist der nächste Schritt nicht das Tooling, sondern die saubere Zerlegung der Datenflüsse in Schichten.
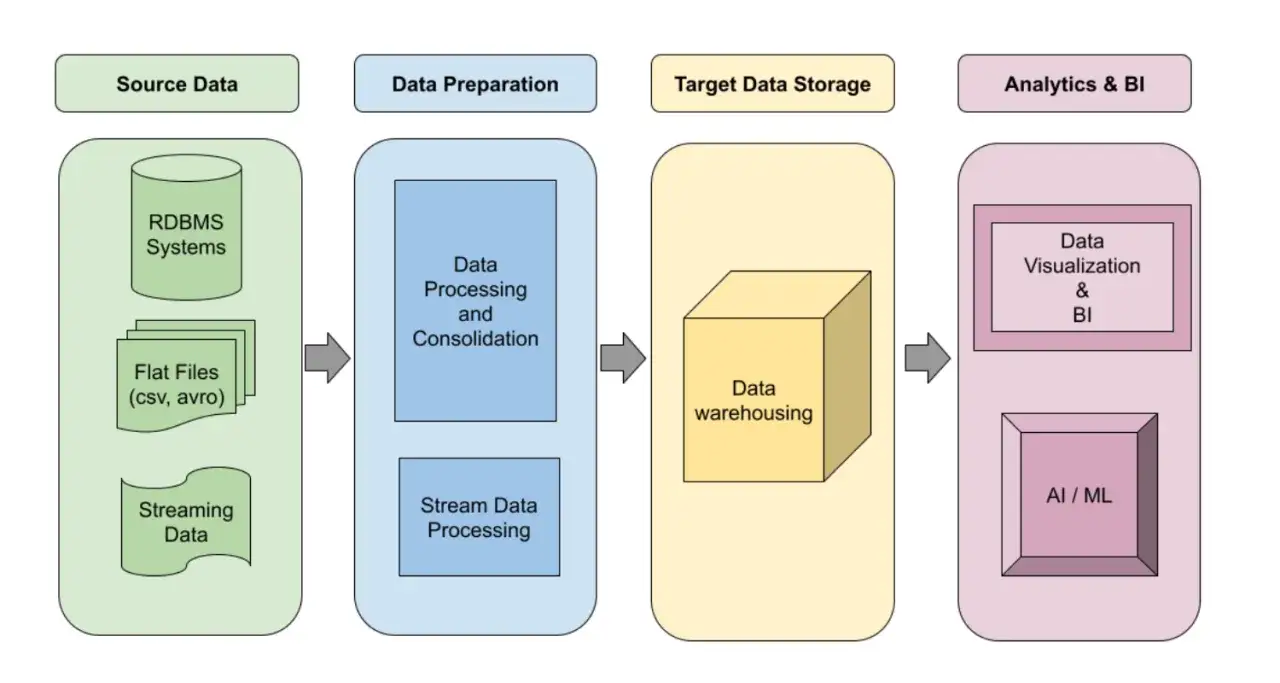
So zerlege ich die Architektur in sinnvolle Schichten
Die meisten Probleme entstehen, wenn Teams zu früh über konkrete Produkte sprechen und zu spät über den logischen Aufbau. Ich trenne deshalb die Architektur in Schichten: Quellen, Ingestion, Rohzone, Transformation, Bereitstellung und Orchestrierung. Diese Trennung klingt unspektakulär, macht aber im Betrieb den größten Unterschied.
| Schicht | Aufgabe | Worauf ich achte |
|---|---|---|
| Quellen | Operative Systeme, APIs, Dateien, Events oder Datenbanken liefern die Rohdaten. | Änderungsrate, Datenformat, Zugriffsmuster und fachliche Verantwortung. |
| Ingestion | Die Daten werden eingesammelt, validiert und in die Plattform übernommen. | Batch, Mikro-Batch oder Streaming, möglichst mit klarer Fehlerbehandlung. |
| Rohzone | Hier landen Daten möglichst unverändert, damit sie reproduzierbar bleiben. | Revisionssicherheit, Versionierung und die Möglichkeit, Läufe neu zu bauen. |
| Transformation | Bereinigung, Verknüpfung, Aggregation und fachliche Modellierung. | Business-Regeln, Schemaänderungen und belastbare Tests. |
| Bereitstellung | Die Daten werden für BI, Ad-hoc-Analysen, Data Science oder Anwendungen nutzbar gemacht. | Abfragemuster, Performance und verständliche Tabellenstrukturen. |
| Orchestrierung | Zeitpläne, Abhängigkeiten, Wiederholungen und Fehlerreaktionen werden gesteuert. | Wiederholbarkeit, Laufzeiten, Alarme und Ownership. |
Der wichtigste praktische Punkt: Ich halte Orchestrierung und Datenfluss gedanklich getrennt. Ein Workflow-Tool steuert, wann etwas passiert; die Pipeline selbst definiert, was mit den Daten geschieht. Diese Trennung verhindert viele spätere Umbauten, weil Logik und Betrieb nicht unnötig miteinander vermischt werden. Wenn das Bild der Schichten steht, wird die Wahl zwischen ETL, ELT und Streaming viel klarer.
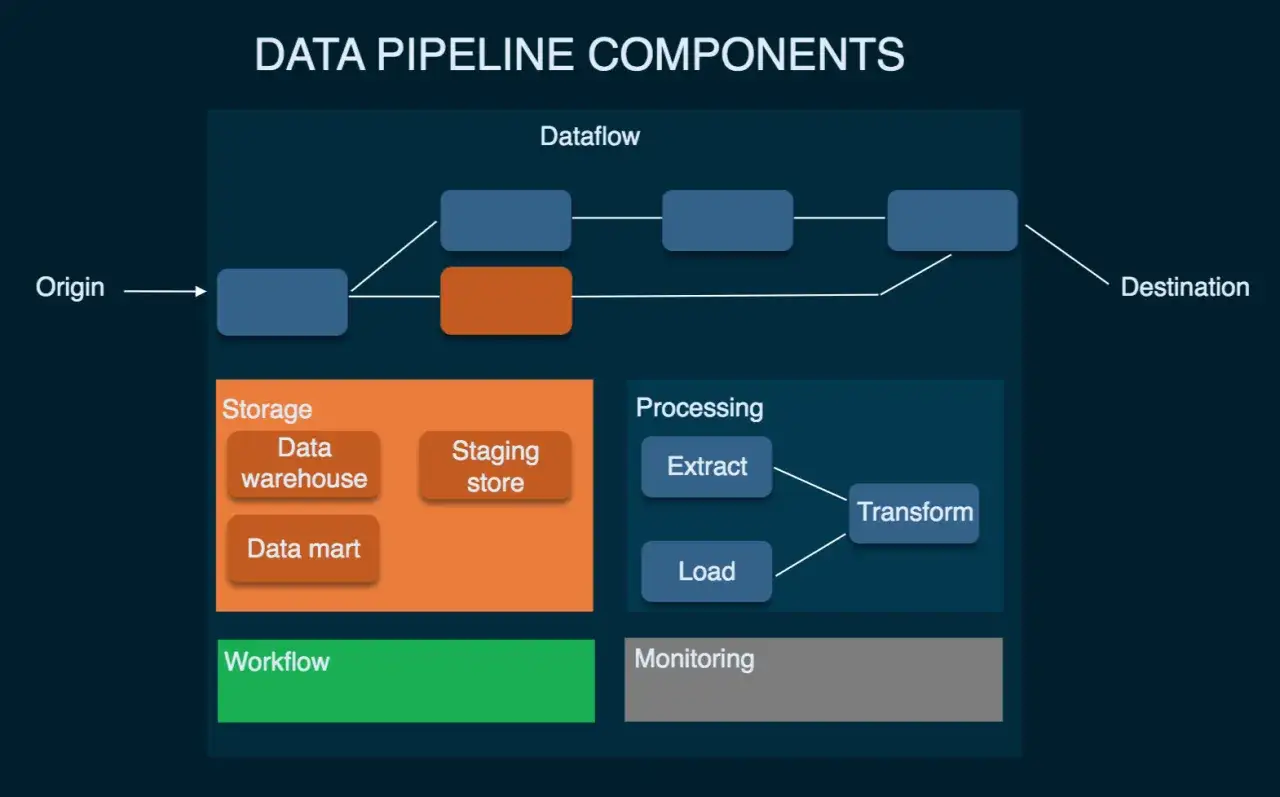
ETL, ELT und Streaming unterscheiden sich stärker als viele Teams glauben
Die Abkürzungen wirken oft wie Varianten derselben Sache, in Wahrheit lösen sie unterschiedliche Probleme. ETL verschiebt die Transformation vor das Zielsystem, ELT nutzt das Zielsystem selbst für die Verarbeitung, und Streaming verarbeitet Daten fortlaufend statt in größeren Paketen. Welche Variante passt, hängt vor allem von der geforderten Aktualität und vom Zielsystem ab.
| Modell | Typische Latenz | Stärken | Schwächen | Sinnvoll, wenn |
|---|---|---|---|---|
| ETL | Minuten bis Stunden | Saubere Kontrolle über Transformationslogik, gut bei klaren Fachregeln. | Mehr Stufen, mehr Wartung, oft höhere Komplexität im Vorfeld. | Die Zielplattform nicht alles selbst leisten soll oder Vorverarbeitung nötig ist. |
| ELT | Minuten bis Stunden | Einfachere Ingestion, Verarbeitung dort, wo die Daten ohnehin liegen. | Das Zielsystem muss die Last tragen können. | Ich ein starkes Warehouse oder Lakehouse habe und viel SQL-Analyse plane. |
| Streaming | Sekunden bis wenige Minuten | Sehr aktuell, ideal für operative Entscheidungen und Event-Daten. | Höhere Komplexität bei Fehlern, Reihenfolge, Deduplizierung und Monitoring. | Aktualität geschäftskritisch ist, etwa bei Betrugserkennung, Lagerbestand oder Live-Dashboards. |
Meine Faustregel ist einfach: Für klassisches Reporting und viele analytische Workloads reicht ELT oft völlig aus. Für Geschäftsprozesse, die auf aktuelle Werte reagieren müssen, braucht man Streaming oder zumindest Change Data Capture, also die Verarbeitung nur der Änderungen statt kompletter Tabellen. Vollständige Reloads wirken anfangs bequem, werden aber bei wachsenden Datenmengen schnell teuer und schwerfällig. Die richtige Antwort hängt jedoch auch davon ab, wo diese Daten am Ende landen: in einem Warehouse, einem Lake oder einem Lakehouse.
Warum Datenbank und Lakehouse das Design bestimmen
Ich plane die Pipeline immer zusammen mit dem Zielsystem. Eine analytische Datenbank, ein klassisches Data Warehouse, ein Data Lake oder ein Lakehouse setzen jeweils andere Schwerpunkte. Wer das ignoriert, baut schnell eine technisch saubere, fachlich aber unpraktische Lösung.
| Zielsystem | Wann es gut passt | Worauf ich besonders achte |
|---|---|---|
| Data Warehouse | Bei stark strukturierten Analysen, BI-Berichten und klaren SQL-Abfragen. | Modellierung, Sternschema, Materialized Views und saubere Berechtigungen. |
| Data Lake | Wenn viele Formate, Rohdaten und flexible Auswertungen zusammenkommen. | Schema-Disziplin, Partitionierung und strenge Governance, sonst wird es schnell unübersichtlich. |
| Lakehouse | Wenn ich Analyse, Transformation und teilweise auch ML auf einer gemeinsamen Schicht verbinden will. | Trennung von Roh-, Zwischen- und Fachdaten sowie robuste Zugriffsregeln. |
Für analytische Datenbanken ist außerdem wichtig, wie die Abfragen aussehen. Viele kleine Lookups, breite Aggregationen und zeitbasierte Scans verlangen andere Strukturen als operative Transaktionen. Deshalb denke ich bei der Modellierung früh an Partitionen, Clusterung, Indizes, aber auch an die Frage, welche Tabellen überhaupt direkt abgefragt werden dürfen. Für Dashboards ist eine gut modellierte Fakt- und Dimensionsebene meist deutlich besser als rohe JSON-Events aus dem Quellsystem. Genau an dieser Stelle hilft eine klare Stufung der Daten besonders stark.
Warum Bronze, Silver und Gold in der Analyse so gut funktionieren
Das Medaillenmodell ist keine Pflicht, aber ein sehr nützliches Ordnungsprinzip. Es trennt Rohdaten, geprüfte Daten und geschäftsreife Daten voneinander und verhindert damit, dass jeder Arbeitsschritt dieselben Daten erneut interpretieren muss. Ich setze es besonders gern ein, wenn mehrere Teams dieselbe Plattform nutzen oder wenn Daten später für Audits, Machine Learning und BI gleichzeitig relevant sind.
- Bronze enthält die Rohdaten so nah wie möglich an der Quelle. Diese Ebene ist wichtig für Reproduzierbarkeit, Rückverfolgung und spätere Neuverarbeitung.
- Silver enthält bereinigte, validierte und oft deduplizierte Daten. Hier werden Fachregeln angewendet, die aus Rohdaten überhaupt erst verlässliche Analyseobjekte machen.
- Gold enthält kuratierte Tabellen, Kennzahlen und Aggregationen für Reporting und Fachanwendungen. Diese Ebene ist auf Nutzung optimiert, nicht auf Roharchivierung.
Der eigentliche Wert liegt nicht in den drei Namen, sondern in der Disziplin, die sie erzwingen. Bronze ist gut für Wiederaufbau und Audit, Silver für Stabilität und fachliche Korrektheit, Gold für Geschwindigkeit und Verständlichkeit. Wer alles direkt in eine einzige Schicht kippt, spart anfangs Zeit, zahlt später aber mit unklaren Abhängigkeiten und fragilen Reports. Damit diese Ordnung nicht nur auf dem Papier existiert, braucht sie Qualitätssicherung und Beobachtbarkeit.
Qualität, Lineage und Monitoring verhindern stille Fehler
Die gefährlichsten Fehler in Datenarchitekturen sind oft nicht die lauten, sondern die stillen. Ein Dashboard mit plausiblen, aber falschen Zahlen ist schlimmer als ein Job, der sofort ausfällt. Genau deshalb gehören Datenqualität, Lineage und Monitoring nicht an den Rand, sondern ins Zentrum der Architektur.
- Datenqualität: Prüfe Schemas, Nullwerte, Wertebereiche, Dubletten und Fremdschlüsselbeziehungen.
- Freshness: Überwache, wie alt die Daten wirklich sind, und definiere klare SLA-Grenzen.
- Lineage: Halte fest, welche Quelle in welche Tabelle und weiter in welchen Bericht fließt.
- Fehlerpfade: Leite problematische Datensätze in einen separaten Bereich statt sie still zu verlieren.
- Benachrichtigungen: Alarme müssen so konkret sein, dass jemand wirklich handeln kann, nicht nur informiert wird.
Lineage ist dabei mehr als Dokumentation. Es zeigt die Abstammung der Daten, also die komplette Kette von Quelle über Transformation bis zur Nutzung. Das ist besonders hilfreich, wenn ein Wert im Reporting plötzlich abweicht und ich die Ursache im Quellsystem, in einer Join-Logik oder in einer Aggregation suchen muss. Ohne diese Sicht baut sich die Fehleranalyse zu einem Ratespiel auf. Deshalb plane ich eine Pipeline nie nur technisch, sondern immer als Betriebsprozess.
So plane ich eine Pipeline in sechs Schritten
Wenn ich ein neues Vorhaben beginne, gehe ich bewusst nicht mit dem Toolkatalog los, sondern mit einem einfachen Arbeitsmodell. Das spart Zeit und verhindert Architekturentscheidungen aus dem Bauch heraus.
- Geschäftsfrage und Aktualitätsbedarf klären. Braucht das Team Tageswerte, stündliche Werte oder nahezu Echtzeit? Diese Antwort entscheidet über Batch, Mikro-Batch oder Streaming.
- Quellen inventarisieren. Ich prüfe, ob die Daten aus Datenbanken, APIs, Dateien oder Event-Streams kommen und wie sich Änderungen erfassen lassen.
- Zielmodell festlegen. Schon früh muss klar sein, ob am Ende ein Warehouse, ein Lakehouse oder eine fachlich modellierte Reporting-Schicht steht.
- Transformationen und Qualitätsregeln definieren. Hier lege ich fest, welche Bereinigungen Pflicht sind und welche Fachlogik in Silver oder Gold gehört.
- Orchestrierung und Betrieb einbauen. Abhängigkeiten, Wiederholungen, Fehlerbehandlung, Rollbacks und Zeitpläne gehören in die Architektur, nicht in ein späteres Nebenprojekt.
- Ownership und Kosten überwachen. Jede Pipeline braucht eine verantwortliche Stelle und ein Gefühl dafür, was Rechenzeit, Speicher und Backfills tatsächlich kosten.
Dieser Ablauf wirkt nüchtern, ist aber in der Praxis sehr robust. Er zwingt dazu, zuerst die Anforderungen zu verstehen und erst dann die technische Form zu wählen. Genau dadurch wird die Architektur einfacher, nicht komplizierter. Die teuersten Probleme entstehen nämlich meist dort, wo Teams zu früh bauen und zu spät merken, dass die Lösung am eigentlichen Bedarf vorbeigeht.
Die Fehler, die in der Praxis am teuersten werden
Es gibt einige Muster, die ich in Projekten immer wieder sehe. Sie wirken am Anfang harmlos, verursachen aber später unverhältnismäßig viel Aufwand.
- Ein riesiger Monolith für alles. Wenn Ingestion, Bereinigung, Business-Logik und Reporting in einem einzigen Job stecken, wird jede Änderung riskant.
- Rohdaten direkt in Dashboards. Das spart kurzfristig Arbeit, führt aber fast immer zu Missverständnissen über Kennzahlen.
- Zu frühe Echtzeit. Nicht jede Fachfrage braucht Sekundenaktualität. Oft reicht eine gut gebaute stündliche oder tägliche Pipeline.
- Keine klaren Schemas. Ohne feste Verträge werden Spaltenumbenennungen und Formatwechsel zu Dauerschäden.
- Fehlende Wiederholbarkeit. Wenn ein Lauf nicht sauber erneut ausgeführt werden kann, fehlt der Architektur ein zentraler Sicherheitsmechanismus.
- Monitoring nur auf Job-Ebene. Ein erfolgreicher Lauf sagt noch nichts darüber aus, ob die Daten fachlich korrekt angekommen sind.
Besonders teuer wird es, wenn ein Team glaubt, Probleme mit mehr Tools lösen zu können. In Wahrheit helfen oft bessere Grenzen, klarere Datenmodelle und ein ehrlicherer Blick auf die Nutzung. Wer diese Stolpersteine kennt, kann die Architektur deutlich nüchterner und damit besser bauen. Am Ende läuft vieles auf drei sehr einfache Entscheidungen hinaus.
Die drei Entscheidungen, die ich am Anfang nie offen lasse
Wenn ich eine neue Pipeline beurteile, stelle ich zuerst drei Fragen: Wie aktuell müssen die Daten wirklich sein, welche Teile müssen historisch nachvollziehbar bleiben, und wer wird die Daten am Ende nutzen? Aus diesen Antworten ergibt sich die Architektur meistens fast von selbst.
- Aktualität: Sekunden, Minuten oder Stunden führen zu sehr unterschiedlichen technischen Lösungen.
- Historie: Rohdaten und Änderungsverläufe gehören in eine Zone, in der ich sie jederzeit neu aufbauen kann.
- Nutzung: BI, operative Anwendungen und Data Science brauchen unterschiedliche Formen der Bereitstellung.
Genau deshalb ist eine gute Pipeline nie nur ein Datenfluss, sondern ein kontrolliertes System für Qualität, Tempo und Vertrauen. Wenn diese drei Dimensionen sauber zusammenkommen, wird Analyse spürbar einfacher und die Datenbank zum belastbaren Werkzeug statt zur Quelle ständiger Nacharbeit.