
Maschinen fallen selten ohne Vorwarnung aus. Genau deshalb setzt moderne Instandhaltung auf Zustandsdaten, Mustererkennung und eine Planung, die sich am realen Verschleiß orientiert. Predictive Maintenance verbindet Sensordaten, Analyse und Wartungsplanung so, dass Eingriffe rechtzeitig, aber nicht zu früh erfolgen. In diesem Artikel geht es darum, wie der Ansatz wirklich funktioniert, welche Daten zählen, wann er sich rechnet und wo Projekte in der Praxis scheitern.
Die wichtigsten Punkte auf einen Blick
- Vorausschauende Instandhaltung verschiebt Wartung von festen Intervallen hin zu konkreten Zustandsdaten.
- Der Nutzen entsteht vor allem bei kritischen Anlagen mit hohen Ausfallkosten oder schwer zugänglichen Komponenten.
- Saubere Daten, klare Fehlerbilder und ein definierter Reaktionsprozess sind wichtiger als ein teures Dashboard.
- Ohne Anbindung an Wartungssoftware und Arbeitsabläufe bleibt der Effekt oft deutlich kleiner als erwartet.
- Ein guter Einstieg beginnt klein, misst einen klaren Business-KPI und wird erst danach skaliert.
Was vorausschauende Instandhaltung in der Praxis bedeutet
Ich trenne in Projekten immer zwischen drei Ebenen: messen, vorhersagen und handeln. Zustandsüberwachung liefert Messwerte wie Temperatur, Vibration oder Stromaufnahme. Erst wenn aus diesen Signalen eine belastbare Prognose entsteht, wird daraus eine vorausschauende Instandhaltungsstrategie. Fraunhofer IML beschreibt den Kern treffend als Prognose über die verbleibende Betriebszeit bis zur nächsten notwendigen Maßnahme.
Der Unterschied zu klassischen Ansätzen ist wichtig. Reaktive Instandhaltung wartet, bis etwas kaputtgeht. Vorbeugende Instandhaltung arbeitet nach Kalender oder Betriebsstunden. Der datenbasierte Ansatz versucht dagegen, den optimalen Zeitpunkt zu treffen: weder zu früh, weil man dann Bauteile unnötig tauscht, noch zu spät, weil der Ausfall bereits eingetreten ist. Genau in dieser Mitte entsteht der wirtschaftliche Hebel.
| Ansatz | Auslöser | Stärke | Schwäche | Typischer Einsatz |
|---|---|---|---|---|
| Reaktiv | Ausfall ist bereits eingetreten | Einfach, kaum Planungsaufwand | Stillstand, Folgeschäden, hohe Unsicherheit | Nicht kritische, gut ersetzbare Komponenten |
| Vorbeugend | Feste Intervalle oder Betriebsstunden | Planbar und organisatorisch leicht | Oft zu früh oder zu spät | Standardisierte Anlagen mit gut bekannten Verschleißmustern |
| Vorausschauend | Zustandsdaten und Prognosemodell | Gezielte Eingriffe, weniger ungeplante Ausfälle | Höhere Anforderungen an Daten, Prozesse und Qualität | Kritische Maschinen, Linien und teure Ausfallrisiken |
Wichtig ist dabei ein Begriff, der oft mitschwingt, aber nicht dasselbe meint: Condition Monitoring, also die laufende Zustandsüberwachung. Es misst, was gerade passiert. Die vorausschauende Instandhaltung nutzt diese Daten, um daraus einen Zeitpunkt oder zumindest ein Risikoniveau für die nächste Maßnahme abzuleiten. Genau an dieser Stelle wird aus Datensammlung operative Steuerung. Damit stellt sich sofort die nächste Frage: Welche Daten tragen das überhaupt?
Welche Daten den Unterschied machen
Die beste Analyse hilft wenig, wenn die Eingaben lückenhaft sind. Für rotierende Maschinen sind Vibration, Temperatur, Schmierung, Druck und Stromaufnahme oft aussagekräftiger als ein einzelner Grenzwertalarm. Bei Fördertechnik kommen Taktzeiten, Lastwechsel, Blockaden und Fehlstellungen hinzu. Bei digitalen Produktionsumgebungen fließen zusätzlich Steuerungsdaten, Ereignisprotokolle und Wartungshistorien ein.
Ich achte besonders auf den Kontext. Ein hoher Stromverbrauch ist nicht automatisch ein Problem, wenn die Maschine gerade unter Volllast läuft. Ein Temperaturanstieg ist ebenfalls nur dann relevant, wenn er aus dem üblichen Betriebsfenster fällt. Ohne Betriebszustand wird aus Messung schnell nur Alarmrauschen. Erst die Kombination aus Signal, Lastprofil, Umgebung und Historie macht die Daten verwertbar.
| Datenquelle | Was sie typischerweise verrät | Worauf ich besonders achte |
|---|---|---|
| Vibration | Lagerfehler, Unwucht, Fluchtungsfehler | Messposition, Drehzahl, Vergleich mit Baseline |
| Temperatur | Reibung, Überlast, Kühlprobleme | Umgebungseinfluss und Lastzustand |
| Stromaufnahme | Mechanische Blockaden, Anlaufprobleme, Effizienzverlust | Normalisierung auf Betriebsmodus und Takt |
| Druck und Durchfluss | Leckagen, Verstopfungen, Pumpenverschleiß | Schwankungen im Prozess und saisonale Effekte |
| Wartungshistorie | Wiederkehrende Fehlerbilder und Reparaturmuster | Saubere Dokumentation und einheitliche Begriffe |
| Steuerungs- und Ereignisdaten | Störungen, Stillstände, fehlerhafte Abläufe | Saubere Zeitstempel und Zuordnung zur Anlage |
Wann sich der Ansatz rechnet und wann nicht
Nicht jede Anlage ist ein guter Kandidat. Ich setze den Ansatz vor allem dort ein, wo ein ungeplanter Stillstand deutlich teurer ist als Analyse und Monitoring. Das betrifft kritische Produktionslinien, schwer zugängliche Maschinen, Anlagen mit wiederkehrenden Defekten und Komponenten, deren Ausfall schnell Folgeschäden erzeugt. Schon ein einziger vermiedener Stopp kann den Business Case stark verbessern, wenn die Linie eng getaktet ist.
Weniger attraktiv ist der Ansatz dort, wo Verschleißteile billig sind, Ausfälle selten auftreten oder sich die Prozessbedingungen ständig ändern. Auch bei Maschinen mit sehr wenig Historie ist Vorsicht sinnvoll. Ein Modell ohne genügend gute Beispiele lernt eher Zufall als Realität. Genau deshalb ist die wirtschaftliche Bewertung immer enger mit der Datenlage verbunden, als viele anfangs denken.
| Gut geeignet | Eher ungeeignet |
|---|---|
| Teure oder kritische Anlagen mit hoher Stillstandssensibilität | Günstige Verschleißteile mit niedrigem Ausfallrisiko |
| Wiederkehrende Fehlerbilder mit klaren Mustern | Stark wechselnde Sonderprozesse ohne stabile Vergleichsdaten |
| Maschinen mit vorhandenen Sensoren, Steuerungsdaten oder Historian-Daten | Anlagen ohne digitale Signale und ohne Dokumentation |
| Systeme mit klarer Reaktion im Wartungsteam | Organisationen ohne Verantwortliche für Alarme und Entscheidungen |
Die eigentliche Rechnung ist deshalb simpel, aber streng: Wie teuer ist ein ungeplanter Ausfall, wie hoch ist der Aufwand für Datenerfassung und Modellierung, und wie sicher lässt sich daraus eine Maßnahme ableiten? Wenn diese drei Größen zueinander passen, entsteht ein realistischer Nutzen. Wenn nicht, sollte man eher mit sauberem Condition Monitoring beginnen, statt sofort ein großes Prognosesystem zu bauen. Daraus folgt der praktische Teil: Wie setzt man einen belastbaren Pilot auf?
Wie ein belastbarer Pilot aufgebaut wird
Für einen ersten Pilot plane ich meist in sechs Schritten. Wenn Historian-Daten, Wartungsprotokolle und ein klarer Verantwortlicher vorhanden sind, sind 8 bis 12 Wochen für einen ersten Durchlauf realistisch; fehlen diese Grundlagen, dauert es spürbar länger. Entscheidend ist nicht die perfekte Plattform, sondern ein sauber abgegrenzter Anwendungsfall.
- Eine konkrete Anlage auswählen. Ich starte mit einer Maschine, bei der ein Fehler wirklich Geld kostet und ein bekanntes Ausfallmuster existiert.
- Einen klaren Fehlerfall definieren. Es reicht nicht zu sagen, dass etwas „ausfällt“. Man braucht ein präzises Zielbild, etwa Lagerschaden, Überhitzung oder Blockade.
- Die relevanten Datenquellen verbinden. Dazu gehören Sensoren, Steuerungsdaten, Wartungsberichte und, falls vorhanden, Schicht- oder Produktionskontext.
- Eine Baseline aufbauen. Das ist der Normalzustand der Maschine. Ohne Baseline gibt es keinen sauberen Vergleich.
- Alarme in einen Arbeitsablauf übersetzen. Ein Modell, das nur ein Dashboard füttert, schafft noch keine Wartung. Die Meldung muss in ein Ticket, eine Prüfung oder einen Auftragsprozess laufen.
- Den Nutzen messen. Ich empfehle einfache Kennzahlen wie vermiedene Stillstände, verringerte Fehlalarme, bessere Planbarkeit und MTBF, also die mittlere Zeit zwischen zwei Ausfällen.
Ein Punkt wird oft unterschätzt: Das Modell ist nicht das Projekt, sondern nur ein Teil davon. Die eigentliche Arbeit steckt in der Datenaufbereitung, in der Definition des Reaktionswegs und in der Frage, wer eine Warnung ernsthaft bearbeitet. Wer diese Punkte früh klärt, spart sich später viel Nacharbeit. Noch wichtiger ist allerdings, die typischen Fehler nicht erst nach dem ersten Fehlalarm zu entdecken.
Welche Fehler Projekte oft ausbremsen
Die meisten Probleme entstehen nicht im Algorithmus, sondern im Umfeld. Zu wenig Daten, unklare Verantwortlichkeiten und schlecht dokumentierte Wartung sind die Klassiker. Ich sehe außerdem oft den Versuch, zu früh zu viel zu wollen: zu viele Anlagen, zu viele Signalquellen, zu viele Ziele gleichzeitig. Das klingt ambitioniert, endet aber häufig in einem System, das vieles anzeigt und wenig wirklich verbessert.
Ein zweiter Stolperstein ist Data Drift. Damit ist gemeint, dass sich das Datenverhalten im Betrieb verändert, etwa nach Umbauten, Produktwechseln oder saisonalen Schwankungen, sodass ein einmal trainiertes Modell an Qualität verliert. Wer das nicht regelmäßig prüft, bekommt still und leise schlechtere Vorhersagen. Ebenso problematisch sind falsche Schwellenwerte, die Alarme entweder inflationär oder zu spät auslösen.
- Zu wenige oder zu schlechte historische Fehlerdaten führen zu schwachen Prognosen.
- Fehlende Wartungsdisziplin macht aus Warnungen bloße Meldungen ohne Konsequenz.
- Zu viele Fehlalarme erzeugen Ignoranz im Team, auch wenn das Modell technisch sauber aussieht.
- Keine Rückkopplung aus der Instandhaltung verhindert, dass das System besser wird.
- Ein zu breiter Start verteilt Aufwand auf zu viele Anlagen und verwässert den Nutzen.
Ich rate deshalb zu einem kleinen, kontrollierten Einstieg. Ein klarer Anwendungsfall, eine messbare Reaktion und eine saubere Lernschleife sind in der Regel wertvoller als eine große Plattform mit unklarem Nutzen. Damit wird auch deutlicher, wo der Ansatz in der Industrie besonders stark ist.
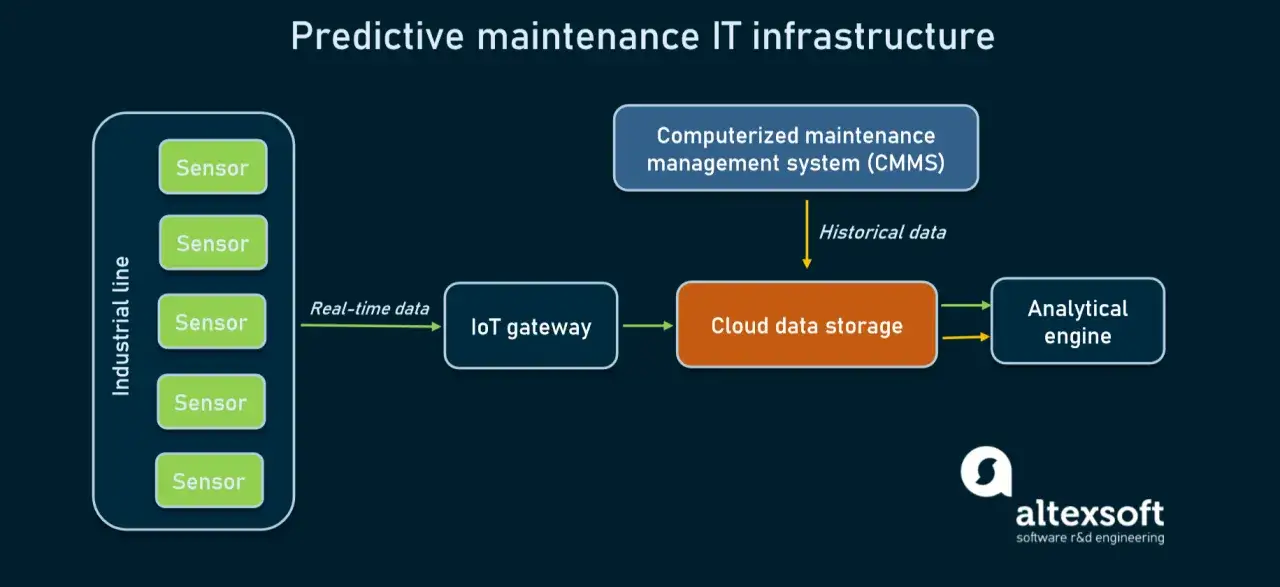
Wo der Nutzen in der Industrie am deutlichsten wird
Besonders anschaulich wird der Nutzen an Fördertechnik, Pumpen, Kompressoren, Motoren, Lagerstellen und thermisch belasteten Anlagen. Gerade in deutschen Produktionsumgebungen lohnt sich der Ansatz häufig bei Retrofit-Projekten, weil vorhandene Steuerungs- und Wartungsdaten oft schon reichen. Es muss also nicht immer eine komplett neue Sensorik sein.
Ein gutes Beispiel liefert die BMW Group in Regensburg. Dort identifiziert ein lernendes System Auffälligkeiten in der Fördertechnik und vermeidet laut Unternehmensangabe jährlich mehr als 500 Minuten Stillstand in der Montage. Der interessante Punkt ist nicht nur die Zahl, sondern die Logik dahinter: Wenn ein einzelnes Transportelement die Linie blockieren kann, ist frühes Eingreifen oft günstiger als reaktive Reparatur oder unnötiger Tausch.
Ähnlich klar ist der Nutzen in anderen Bereichen:
- Fördertechnik profitiert von wiederkehrenden Bewegungsprofilen und klaren Störmustern.
- Pumpen und Kompressoren liefern oft gut auswertbare Signale über Vibration, Druck und Temperatur.
- Robotik und CNC-Anlagen reagieren empfindlich auf Abweichungen im Takt, in der Last oder in der Positionierung.
- Gebäudetechnik lohnt sich besonders dann, wenn viele ähnliche Aggregate zentral überwacht werden.
- Energie- und Prozessanlagen bieten oft hohe Einsparpotenziale, weil Ausfälle teuer und die Sicherheitsanforderungen hoch sind.
Was ich daran wichtig finde: Der stärkste Effekt entsteht fast nie durch ein einzelnes Modell allein, sondern durch das Zusammenspiel aus Daten, Arbeitsprozess und technischer Disziplin. Wer das versteht, vermeidet den häufigsten Denkfehler, nämlich den Ansatz als reines IT-Projekt zu behandeln.
Welche drei Fragen den ersten Rollout tragen
Wenn ich einen ersten Rollout aufsetzen müsste, würde ich mich auf drei Fragen beschränken: Welcher konkrete Fehlerfall kostet am meisten, welche Signale beschreiben ihn zuverlässig, und wer reagiert im richtigen Zeitfenster auf eine Warnung? Diese drei Punkte entscheiden mehr über den Erfolg als die Wahl eines bestimmten Tools. Ein sauberes Setup ist oft weniger spektakulär, aber deutlich wirksamer als ein großes, schwer steuerbares System.
Wer den Einstieg klein, datenbewusst und eng an einem realen Wartungsproblem plant, bekommt kein Buzzword-Projekt, sondern ein Instrument für planbare Verfügbarkeit. Genau darin liegt der eigentliche Wert: weniger Überraschung, mehr Steuerbarkeit und bessere Entscheidungen im laufenden Betrieb.