
Ein gut gebautes analytisches Modell entscheidet oft mehr über die Qualität von Berichten als das Dashboard selbst. Das Snowflake-Schema gehört zu den Designs, die ich dann einsetze, wenn Dimensionen sauber strukturiert, Stammdaten konsistent gehalten und hierarchische Auswertungen nachvollziehbar bleiben sollen. Im Englischen spricht man von einem snowflake schema; im Deutschen wird oft auch vom Schneeflockenschema gesprochen.
Die zentrale Idee in drei Punkten
- Die Faktentabelle bleibt im Zentrum, aber Dimensionen werden in mehrere normalisierte Tabellen zerlegt.
- Redundanz sinkt, dafür steigen die Zahl der Joins und damit meist auch die Modellkomplexität.
- Besonders sinnvoll ist das Modell bei klaren Hierarchien, wiederverwendeten Unterdimensionen und strenger Datenpflege.
- Für Self-Service-Analysen ist ein Sternschema oft leichter zu verstehen und schneller abzufragen.
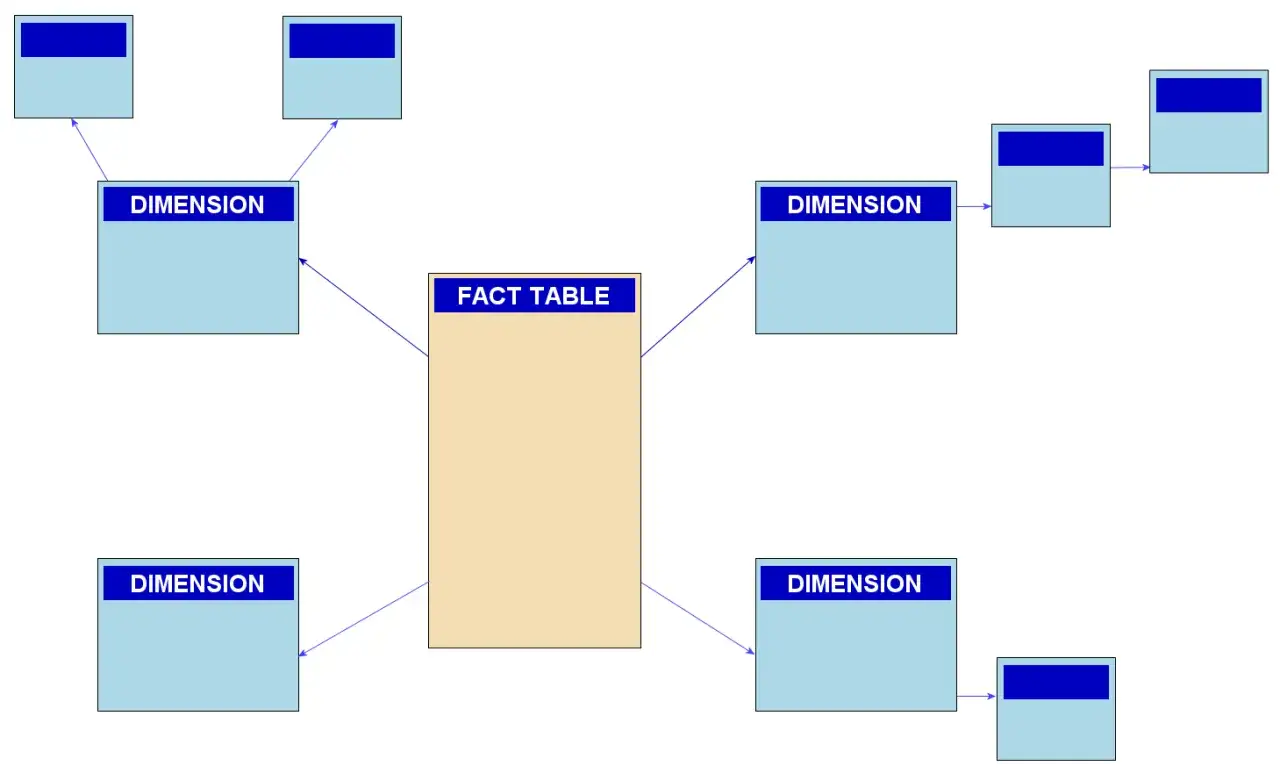
Wie das Snowflake-Schema aufgebaut ist
Ich lese so ein Modell immer von der Faktentabelle aus. Dort liegen die messbaren Ereignisse, also etwa Umsatz, Menge, Kosten oder Klicks. Die Dimensionen liefern den Kontext: Produkt, Datum, Kunde, Standort oder Kampagne. Im Schneeflockenmodell wird dieser Kontext nicht in einer einzigen breiten Tabelle abgelegt, sondern in mehrere Tabellen zerlegt, wenn eine Dimension selbst wieder Hierarchien oder Untergruppen enthält.
Ein typisches Beispiel ist die Produktdimension. Statt alle Attribute in einer Tabelle zu halten, wird sie in mehrere Ebenen aufgeteilt: Produkt, Unterkategorie und Kategorie. So entsteht eine Struktur mit vielen Beziehungen von eins zu vielen beziehungsweise aus analytischer Sicht mit vielen Many-to-one-Verknüpfungen Richtung Faktentabelle. Das spart Wiederholungen, weil Kategorienamen nicht in jeder Produktzeile neu stehen müssen.
- Faktentabelle enthält die Kennzahlen und Fremdschlüssel.
- Dimensionstabellen beschreiben die Analyseachsen.
- Unterdimensionen bilden Hierarchien wie Kategorie, Unterkategorie und Produkt ab.
- Joins holen die Informationen bei der Abfrage zusammen.
Genau deshalb wirkt das Modell wie eine Schneeflocke: Aus einem Zentrum verzweigen mehrere Ebenen nach außen. Der Preis dafür ist klar, und darauf komme ich gleich: Mehr Struktur bedeutet fast immer auch mehr Verknüpfungen. Damit stellt sich sofort die nächste Frage, nämlich wann diese zusätzliche Ordnung wirklich nützt.
Wann sich die Normalisierung wirklich lohnt
Ich setze ein Snowflake-Schema vor allem dann in Betracht, wenn Dimensionen nicht nur Beschriftungen liefern, sondern echte Hierarchien enthalten. Das ist bei Produkten, geografischen Strukturen, Organisationen oder Zeitdimensionen sehr häufig der Fall. Sobald dieselben Oberbegriffe in vielen Berichten wiederkehren, reduziert Normalisierung die Pflegearbeit und verhindert, dass kleine Abweichungen in den Stammdaten überall anders auftauchen.
Der zweite gute Grund ist geteilte Referenzlogik. Wenn mehrere Fachbereiche dieselbe Kategorie- oder Regionenlogik nutzen, ist eine zentrale Aufteilung oft sauberer als das Kopieren derselben Texte in viele breite Tabellen. Ich sehe das besonders dort, wo Datenqualität wichtiger ist als maximale Bequemlichkeit für Ad-hoc-Abfragen.
- Wiederkehrende Werte wie Länder, Kategorien oder Abteilungen tauchen in vielen Zeilen auf.
- Hierarchien sollen exakt und konsistent bleiben, etwa Produkt → Untergruppe → Hauptgruppe.
- Stammdatenpflege ist zentral organisiert und Änderungen sollen an einer Stelle wirken.
- Quellsysteme sind bereits normalisiert, und eine 1:1-Übernahme vermeidet doppelte Transformationslogik.
Wichtig ist für mich die Erwartungskorrektur: Das Modell spart Redundanz, aber es ist kein magischer Performance-Hebel. Es lohnt sich vor allem dort, wo Struktur und Governance schwerer wiegen als die letzte Millisekunde in einem einfachen Bericht. Genau deshalb lohnt sich der direkte Vergleich mit dem Sternschema.
Wo es gegenüber dem Sternschema verliert
In der Praxis ist das Sternschema oft der erste Reflex, weil es für Analysten leichter zu lesen ist. Das Schneeflockenmodell ist anspruchsvoller, und dieser Nachteil zeigt sich in mehreren Punkten ziemlich direkt. Ich fasse die wichtigsten Unterschiede so zusammen:
| Kriterium | Snowflake-Schema | Sternschema | Praktische Folge |
|---|---|---|---|
| Abfragegeschwindigkeit | Oft langsamer wegen mehr Joins | Meist schneller und direkter | Berichte reagieren einfacher, wenn weniger Tabellen beteiligt sind. |
| Redundanz | Niedrig | Höher | Weniger doppelte Werte, aber mehr Tabellenpflege im Modell. |
| Modellkomplexität | Höher | Niedriger | Neue Teammitglieder brauchen mehr Einarbeitung. |
| Self-Service-Nutzung | Weniger intuitiv | Sehr intuitiv | Fachanwender finden sich in flachen Modellen schneller zurecht. |
| Hierarchien | Sauber abbildbar | Oft in einer breiten Tabelle | Mehrstufige Strukturen bleiben logisch getrennt. |
| Datenpflege | Zentral und konsistent | Mehrfach dupliziert | Änderungen an Kategorien müssen nicht an mehreren Stellen korrigiert werden. |
Ich würde es so formulieren: Das Sternschema gewinnt fast immer bei Einfachheit, das Schneeflockenschema bei Ordnung und Wiederverwendbarkeit. Welche Seite besser ist, hängt nicht von der Theorie ab, sondern davon, wer die Daten später nutzt und wie oft sich die Dimensionen ändern. Damit kommen wir zu einem konkreten Beispiel, denn dort sieht man den Unterschied am schnellsten.
Ein realistisches Beispiel aus dem Vertrieb
Nehmen wir einen Vertrieb, der Umsätze nach Produktkategorie, Region und Monat auswerten will. Die Faktentabelle enthält Bestellungen oder Rechnungspositionen, also Messwerte wie Umsatz, Rabatt und Menge. Die Produktinformationen werden normalisiert, weil mehrere Produkte zur gleichen Unterkategorie gehören und mehrere Unterkategorien wiederum zur gleichen Kategorie.
| Tabelle | Rolle | Wichtige Spalten |
|---|---|---|
| fact_sales | Faktentabelle | date_id, product_id, customer_id, revenue, quantity |
| dim_product | Produktdetails | product_id, subcategory_id, product_name |
| dim_subcategory | Unterkategorie | subcategory_id, category_id, subcategory_name |
| dim_category | Oberkategorie | category_id, category_name |
| dim_date | Zeitdimension | date_id, month, quarter, year |
Wenn ich jetzt den Umsatz nach Kategorie und Monat abfrage, läuft die Verknüpfung über mehrere Stufen: Faktentabelle → Produkt → Unterkategorie → Kategorie und zusätzlich zur Datumsdimension. Das sind schnell vier Joins statt zwei. Funktional ist das sauber, aber eben nicht so bequem wie eine breite Produkttabelle mit bereits aufgelöster Kategorie.
Der Gewinn liegt an anderer Stelle: Wenn sich die Kategoriebezeichnungen ändern, wird die Änderung an einer Stelle gepflegt. Und wenn dieselbe Kategorie in 20 Berichten vorkommt, bleibt die Logik überall identisch. Genau das ist der Punkt, an dem Normalisierung in Analysemodellen ihren praktischen Wert beweist. Trotzdem bleibt die Umsetzung anfällig für typische Fehler.
Typische Fehler bei Design und Umsetzung
Die meisten Probleme entstehen nicht durch das Konzept selbst, sondern durch falsche Erwartungen an seine Rolle. Ich sehe dabei immer wieder dieselben Stolpersteine:
- Zu viele Ebenen - Drei oder vier Tabellen für eine einzige Dimension sind noch gut erklärbar; darüber wird die Abfragekette schnell unübersichtlich.
- Kleine Dimensionen unnötig zerlegen - Wenn eine Tabelle nur wenige Dutzend Zeilen hat, bringt zusätzliche Normalisierung kaum echten Nutzen.
- Schlüssel unsauber definieren - Ohne stabile technische Schlüssel werden Beziehungen fragil und Auswertungen fehleranfällig.
- Hierarchien nicht dokumentieren - Wer nicht versteht, welche Ebene wofür steht, baut Berichte auf unsicherer Basis.
- Das Modell direkt an Endanwender ausspielen - Fachanwender wollen meist nicht über drei Tabellen hinweg denken, sondern mit klaren Feldern arbeiten.
- Performance als einzige Begründung nehmen - Weniger Redundanz klingt gut, ersetzt aber keine Messung der tatsächlichen Abfragekosten.
Mein praktischer Rat ist simpel: Erst Modellgrenzen, dann Nutzungsszenarien definieren, erst danach die Tabellen zerlegen. Wer das umdreht, optimiert gern an der falschen Stelle. Die moderne Datenlandschaft macht diese Abwägung nicht einfacher, aber sie gibt bessere Werkzeuge dafür.
Wann ich das Modell heute noch einsetzen würde
Auch 2026 ist das Schneeflockenmodell kein Allzweckstandard, aber es bleibt relevant. In modernen Lakehouse- und BI-Umgebungen würde ich es dann einsetzen, wenn die Fachlogik stark hierarchisch ist, wenn Stammdaten zentral gepflegt werden und wenn mehrere Teams dieselbe Dimension konsistent nutzen sollen. Besonders bei Produkt-, Kunden- und Organisationsdaten kann das sehr sauber funktionieren.
Gleichzeitig würde ich die Nutzerschicht entkoppeln. Die Roh- oder Integrationsschicht darf normalisiert sein, die semantische Schicht für Berichte aber gern flacher. Genau diese Trennung ist oft der beste Kompromiss: intern präzise, außen bedienbar. Wenn Self-Service dominiert, flache Modelle oder Views meist besser; wenn Governance und Wiederverwendbarkeit wichtiger sind, hat die Schneeflockenstruktur klare Vorteile.
- Ja, wenn Hierarchien real sind und regelmäßig gemeinsam ausgewertet werden.
- Ja, wenn dieselben Unterdimensionen mehrfach gebraucht werden.
- Ja, wenn Datenpflege und Konsistenz schwerer wiegen als maximale Einfachheit.
- Eher nein, wenn Analysten direkt und ohne Schulung arbeiten sollen.
- Eher nein, wenn jede zusätzliche Join-Stufe schon im Entwurf ein Risiko ist.
Meine Faustregel lautet deshalb: Wenn ich ein Analysemodell für robuste, nachvollziehbare Stammdaten bauen soll, ist das Schneeflockenschema eine saubere Wahl. Wenn das Hauptziel schnelle, leicht lesbare Ad-hoc-Analysen für viele Nutzer ist, flache ich die Dimensionen lieber in einer semantischen Schicht ab und lasse die Komplexität nicht bis zum Bericht durchlaufen.