
Ein modernes Datenfundament muss heute zwei Dinge gleichzeitig leisten: verlässliches Reporting und flexible Analysen bis hin zu Machine Learning und generativer KI. Genau hier setzt die data lakehouse architecture an, weil sie die Offenheit eines Data Lake mit den Kontroll- und Analysefunktionen eines Data Warehouse verbindet. In diesem Beitrag zeige ich, wie der Ansatz aufgebaut ist, wann er sich lohnt, wo seine Grenzen liegen und wie ich ihn in einem Projekt pragmatisch aufsetzen würde.
Die wichtigsten Punkte auf einen Blick
- Ein Lakehouse reduziert Datenkopien, indem Rohdaten, Analyse und Governance auf einer gemeinsamen Basis laufen.
- Technisch tragen vor allem offene Tabellenformate, ein sauberer Katalog und klare Zugriffsregeln die Architektur.
- Der große Nutzen entsteht, wenn BI, Data Engineering und Data Science auf dieselben kontrollierten Daten zugreifen.
- Ohne Datenqualität, Ownership und Betriebsdisziplin wird aus dem Lakehouse schnell nur ein besser benannter Datenspeicher.
- Für rein SQL-lastige Reporting-Szenarien kann ein klassisches Warehouse weiterhin die einfachere Wahl sein.
Was das Lakehouse in der Praxis löst
Der Kern des Problems ist altbekannt: Ein Data Lake ist flexibel und günstig, aber oft zu roh für saubere Analytik. Ein Data Warehouse ist analytisch stark, verlangt aber mehr Modellierung, mehr Kopien und meistens mehr Disziplin beim Laden. Das Lakehouse versucht, diese Trennung aufzulösen, damit Daten nicht ständig zwischen Systemen hin- und hergeschoben werden müssen.
Ich sehe den größten Mehrwert dort, wo Organisationen gleichzeitig strukturierte und unstrukturierte Daten haben, aber nicht für jeden Anwendungsfall eine eigene Plattform betreiben wollen. Statt Rohdaten im Lake, Kennzahlen im Warehouse und Extrakopien für Data Science zu pflegen, entsteht eine gemeinsame Schicht, auf der unterschiedliche Teams arbeiten können.
- Weniger Datensilos bedeuten meist weniger Inkonsistenzen in Kennzahlen und weniger Diskussionen über „welche Zahl stimmt denn nun“.
- Einheitlicher Zugriff erleichtert es, BI, Exploration und Modellentwicklung auf derselben Datenbasis zu betreiben.
- Weniger Kopien reduzieren Pflegeaufwand, Storage-Sprawl und die Gefahr veralteter Ableitungen.
Genau deshalb ist das Lakehouse kein bloßer Trendbegriff, sondern eine Antwort auf ein sehr praktisches Betriebsproblem. Damit ist die Ausgangslage klar, und jetzt lohnt sich der Blick auf die Bausteine, aus denen die Architektur wirklich besteht.
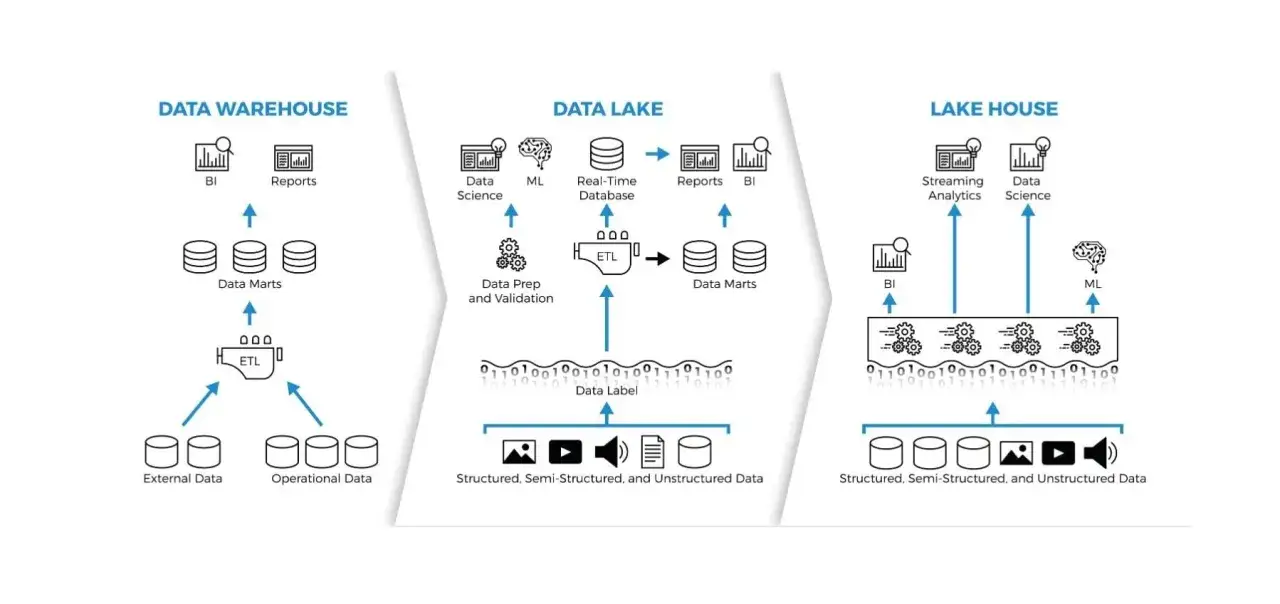
So ist eine belastbare Lakehouse-Architektur aufgebaut
Wenn ich eine Lakehouse-Architektur prüfe, zerlege ich sie gedanklich in vier Ebenen: Speicher, Tabellenformat, Governance und Verarbeitung. Erst wenn diese Teile sauber zusammenarbeiten, wird aus einem Datensee ein belastbares Analysefundament.
Objektspeicher und offene Tabellenformate
Am Anfang steht fast immer kostengünstiger Cloud-Objektspeicher. Darauf liegen die Daten nicht einfach als lose Dateien herum, sondern idealerweise in einem offenen Tabellenformat wie Delta Lake oder Apache Iceberg. Der Unterschied ist wichtig: Das Tabellenformat bringt Dinge mit, die man in einem klassischen Data Lake oft vermisst, etwa ACID-Transaktionen, Schema-Prüfung und nachvollziehbare Versionen.
ACID steht für Atomarität, Konsistenz, Isolation und Dauerhaftigkeit. Praktisch heißt das: Datenänderungen brechen nicht halb durch, konkurrierende Schreibvorgänge werden kontrolliert, und Auswertungen laufen nicht gegen widersprüchliche Zwischenstände. Genau das macht das Lakehouse für produktive Analytik deutlich robuster.
Katalog, Rechte und Governance
Die zweite Schicht ist für mich der eigentliche Reifegradtest. Ein guter Katalog weiß, welche Tabellen existieren, wer sie besitzt, welche Spalten sensibel sind und wer lesen oder schreiben darf. Ohne diese Ebene bleibt das Lakehouse zwar technisch attraktiv, aber organisatorisch fragil.
Hier entscheidet sich auch, ob das Modell nur für ein kleines Team funktioniert oder unternehmensweit skaliert. Rollen, Zugriffspfade, Klassifizierung und Auditierbarkeit müssen früh mitgedacht werden, nicht erst dann, wenn schon mehrere Fachbereiche darauf arbeiten. Das ist der Punkt, an dem viele Projekte unterschätzen, wie wichtig saubere Datenprodukte und klar benannte Verantwortlichkeiten sind.
Verarbeitung für Batch, Streaming und SQL
Ein starkes Lakehouse unterstützt typischerweise mehrere Arbeitsweisen gleichzeitig. Data Engineers laden und transformieren Daten, Analysten greifen per SQL zu, Data Scientists nutzen Notebooks, und Streaming-Jobs verarbeiten Ereignisse nahezu in Echtzeit. Der Vorteil liegt nicht darin, alles in einem Werkzeug zu erzwingen, sondern in einer gemeinsamen Datenbasis für unterschiedliche Nutzungsmuster.
Wichtig ist dabei die Entkopplung von Compute und Storage. So lassen sich Rechenlasten je nach Bedarf skalieren, ohne die Daten jedes Mal zu verschieben. Das hilft besonders dann, wenn Lastspitzen nicht vorhersehbar sind oder mehrere Teams unabhängig voneinander arbeiten.
Lesen Sie auch: Data Engineering erklärt - Brücke von Daten zu Entscheidungen
Bronze, Silver und Gold als Arbeitsmodell
In der Praxis hat sich die Medallion- oder Mehrschichtenlogik bewährt. Rohdaten landen in der Bronze-Schicht, bereinigte und validierte Daten in Silver, und fachlich angereicherte Daten in Gold. Ich halte dieses Modell nicht für Pflicht, aber für sehr nützlich, weil es den Datenfluss verständlich macht und Qualitätsstufen sichtbar hält.
Der große Vorteil ist die Nachvollziehbarkeit: Man sieht, wo Daten noch roh sind, wo sie geprüft wurden und wo sie bereits für BI oder Fachprozesse optimiert sind. Damit wird die Architektur nicht nur technisch, sondern auch für Teams lesbar. Und genau das führt direkt zur Frage, wann sich dieser Ansatz gegenüber klassischen Alternativen wirklich auszahlt.
Wann sie Data Lake und Warehouse wirklich schlägt
Die ehrliche Antwort lautet: nicht immer. Ein Lakehouse ist dort stark, wo Sie verschiedene Datentypen, Analyseformen und Governance-Anforderungen auf einer gemeinsamen Plattform zusammenführen wollen. Wenn Ihr Umfeld dagegen fast ausschließlich aus hochstandardisiertem SQL-Reporting besteht, kann ein klassisches Warehouse weiterhin einfacher und effizienter sein.
| Kriterium | Data Lake | Data Warehouse | Lakehouse |
|---|---|---|---|
| Datentypen | Sehr flexibel, auch unstrukturiert | Vor allem strukturiert | Strukturiert, halbstrukturiert und unstrukturiert |
| Analyse | Gut für Exploration, aber oft roh | Stark für BI und standardisierte Reports | Stark für BI, Data Science und gemischte Workloads |
| Governance | Oft nachgelagert und uneinheitlich | Meist ausgereift | Wenn sauber umgesetzt, auf einer gemeinsamen Schicht |
| Kostenstruktur | Günstiger Speicher, aber hoher Integrationsaufwand möglich | Oft teurer bei großen, stark modellierten Umgebungen | Günstiger als Doppelstrukturen, aber nur bei sauberem Betrieb |
| Typische Stärke | Rohdaten aufnehmen | Vertrauenswürdiges Reporting | Eine Plattform für beides |
| Typische Schwäche | Chaos ohne Ordnung | Wenig flexibel für neue Datenarten | Mehr Architekturdisziplin nötig als viele erwarten |
Meine praktische Faustregel: Wenn Daten in vielen Formen ankommen, verschiedene Teams dieselbe Wahrheit nutzen sollen und BI sowie ML nebeneinander stehen, ist das Lakehouse meist die klügere Architektur. Wenn dagegen alles um ein kleines Set sauberer, relationaler Reports kreist, ist ein Warehouse oft schneller auf den Punkt gebracht. Die Entscheidung fällt also weniger ideologisch als vielmehr entlang des realen Workloads.
Damit ist die Wahl zwischen den Modellen greifbar; im nächsten Schritt geht es darum, wie man ein Lakehouse so aufsetzt, dass es im Alltag nicht wieder zerfällt.
Wie ich ein Lakehouse in fünf Schritten aufbaue
Ein gutes Projekt beginnt nicht mit Tools, sondern mit Klarheit. Ich würde immer zuerst die wichtigsten Anwendungsfälle, Datenquellen und Verantwortlichkeiten festziehen, bevor ich die Plattform auswähle oder Tabellen modelliert werden.
- Use Cases und Domänen abgrenzen. Welche Berichte, Analysen und Modelle sollen zuerst abgedeckt werden, und welche Fachbereiche tragen Verantwortung?
- Rohdaten unverändert aufnehmen. Die erste Zone sollte alles nachvollziehbar speichern, damit Herkunft und Historie erhalten bleiben.
- Tabellenformat und Schema-Regeln festlegen. Ohne Schema Enforcement, Versionierung und ein klares Datenmodell wird die Qualität schnell unübersichtlich.
- Qualitätsprüfungen und Transformationspfade definieren. Validierung, Duplikaterkennung, Ableitung und Aggregation gehören in eine reproduzierbare Pipeline.
- Verbrauchsschicht sauber veröffentlichen. BI-Teams, Data Scientists und operative Anwendungen brauchen unterschiedliche, aber konsistente Sichten auf dieselben Daten.
Besonders wichtig ist für mich dabei die Betriebsseite: Logging, Monitoring, Kostenkontrolle und Wiederherstellbarkeit müssen von Anfang an mitlaufen. Ein Lakehouse ist nicht dann gut, wenn die Demo überzeugt, sondern wenn es nach drei Monaten im Betrieb noch verständlich, schnell und beherrschbar bleibt. Genau dort passieren die meisten Fehler, wenn Teams zu optimistisch starten.
Wenn diese fünf Schritte stehen, ist die Architektur zwar noch nicht perfekt, aber sie ist belastbar genug, um die üblichen Stolperfallen sichtbar zu machen.
Typische Fehler, die Lakehouse-Projekte ausbremsen
Der häufigste Fehler ist aus meiner Sicht, das Lakehouse als bloßen Sammelort für Daten zu behandeln. Dann entsteht nur ein hübscheres Rohdatenarchiv, aber keine verlässliche Analyseplattform.
- Kein Ownership-Modell: Wenn niemand fachlich verantwortlich ist, verkommt jede Schicht zur Zwischenablage.
- Zu wenig Qualitätsregeln: Ohne Prüfungen werden fehlerhafte Daten nur schneller verteilt.
- Unklare Semantik: Wenn Kennzahlen nicht eindeutig definiert sind, hilft auch die beste Plattform nicht.
- Warehouse-Denken 1:1 kopieren: Ein Lakehouse braucht andere Optimierungs- und Betriebsentscheidungen als ein klassisches DWH.
- Governance zu spät einbauen: Berechtigungen, Sensitivitätsklassen und Auditierbarkeit sind Fundament, nicht Zusatzmodul.
Ein weiterer Punkt wird gern unterschätzt: Nicht jedes Team braucht sofort volle Selbstbedienung. In manchen Organisationen ist ein kontrollierter Einstieg mit wenigen, sehr sauberen Datenprodukten deutlich wirksamer als ein breit geöffnetes System ohne Leitplanken. So wird das Lakehouse nicht zum politischen Experiment, sondern zu einem stabilen Betriebsmittel.
Genau an dieser Stelle wird auch der Reifegrad sichtbar, den ich im Alltag als Nächstes prüfe.
Woran ich 2026 die Reife eines Lakehouse bewerte
Wenn ich heute auf eine Lakehouse-Umgebung schaue, interessiere ich mich weniger für die Marketingfolie als für einige sehr konkrete Signale. Sie sagen oft mehr über den tatsächlichen Zustand aus als jede Architekturzeichnung.
- Gibt es einen zentralen Katalog mit klaren Besitzern und nachvollziehbaren Rechten?
- Sind sensible Daten klassifiziert, maskiert oder regelbasiert geschützt?
- Lassen sich Datenänderungen versionieren, prüfen und bei Bedarf reproduzieren?
- Gibt es definierte Qualitätschecks für kritische Pipelines und Tabellen?
- Können BI, Engineering und Data Science auf dieselbe kontrollierte Datenbasis zugreifen?
Wenn diese Punkte sauber beantwortet sind, dann ist ein Lakehouse mehr als ein Buzzword. Dann entsteht eine Plattform, die Daten nicht nur speichert, sondern nutzbar, nachvollziehbar und sicher macht. Genau darin liegt für mich der eigentliche Wert dieses Ansatzes: Er vereinfacht nicht die Datenwelt selbst, aber er macht sie beherrschbarer.