
Saubere Analysen stehen und fallen mit der Frage, woher die Zahlen kommen und was mit ihnen unterwegs passiert. Data lineage beschreibt genau diese Rückverfolgung von Daten über Quellen, Transformationen und Zielsysteme hinweg. Für Datenanalyse und Datenbanken ist das kein Luxus, sondern die Grundlage für verlässliche Reports, schnelle Fehleranalyse und belastbare Governance.
Die wichtigsten Punkte auf einen Blick
- Datenherkunft dokumentiert Quelle, Verarbeitungsschritte, Ziel und oft auch Verantwortlichkeiten.
- Auf Tabellenebene reicht sie für grobe Abhängigkeitsanalysen, auf Spaltenebene wird sie für präzise Prüfungen deutlich wertvoller.
- Besonders nützlich ist sie bei Root-Cause-Analysen, Impact Analysis, Migrationen, Audits und Qualitätsproblemen.
- Automatisierte Erfassung skaliert gut, verpasst aber oft Sonderfälle; manuelle Pflege ist präzise, aber teuer.
- Der größte Fehler ist ein hübscher Metadaten-Graph ohne aktuelle, wirklich vollständige Abdeckung.
Was Datenherkunft in Analyseprojekten wirklich bedeutet
In der Praxis geht es nicht nur um die Frage, aus welchem System ein Datensatz stammt. Ich will wissen, welche Transformation ihn verändert hat, welche Version verwendet wurde und wo das Ergebnis landet - zum Beispiel in einem Data Warehouse, einem BI-Report oder einem Machine-Learning-Feature-Store. Erst diese Kette macht Daten nachvollziehbar.Man kann das auf zwei Ebenen betrachten. Auf der Tabellenebene sieht man, welche Datenquellen eine Tabelle speisen und welche Zielobjekte davon abhängen. Auf der Spaltenebene wird es präziser: Dann lässt sich etwa nachvollziehen, wie aus `customer_id`, `order_date` und einer Bereinigungsregel ein KPI wie „aktive Kunden“ entsteht. Genau diese Granularität entscheidet oft darüber, ob ein Audit oder eine Fehlersuche in Minuten oder in Tagen erledigt ist.
Wichtig ist auch der Unterschied zwischen Datenfluss und Metadaten-Notiz. Ein sauberer Herkunftsnachweis ist kein statischer Wiki-Eintrag, sondern ein lebender Zusammenhang aus Objekt, Prozess und Zeit. Wenn diese Grundlage steht, lässt sich der tatsächliche Ablauf als Graph viel besser lesen. Wie dieser Graph aussieht, ist der nächste praktische Schritt.
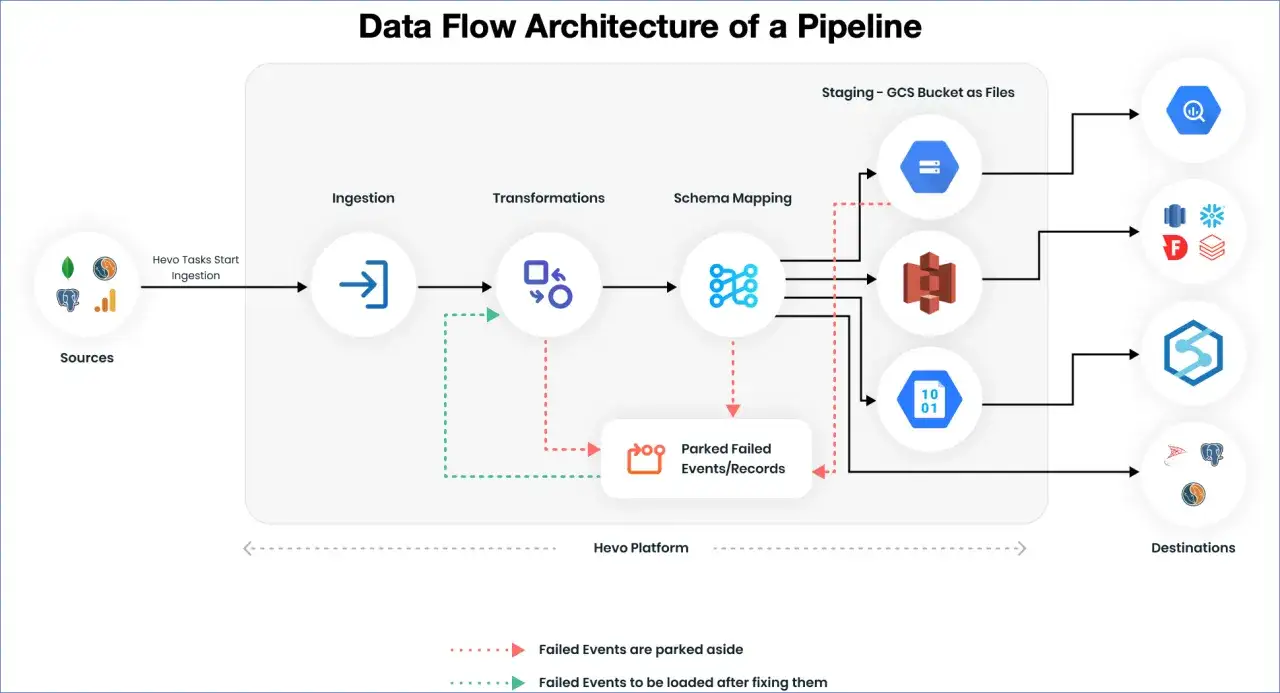
So entsteht ein nachvollziehbarer Datenpfad in der Praxis
Ein brauchbarer Lineage-Graph verbindet drei Dinge: Quellen, Verarbeitungsschritte und Ziele. Die Knoten sind Tabellen, Views, Jobs, Notebooks, SQL-Skripte oder Dashboards; die Kanten zeigen, was aus was entstanden ist. Bei modernen Plattformen wird häufig zwischen Design-Time-Lineage und Runtime-Lineage unterschieden. Ersteres beschreibt den geplanten Aufbau, letzteres die tatsächlich ausgeführte Verarbeitung.
Für Analyseumgebungen ist das entscheidend, weil sich die Realität fast immer vom Entwurf unterscheidet. Ein SQL-Job kann je nach Parameter andere Tabellen lesen, ein Notebook kann ad hoc angepasst werden, und ein BI-Tool kann über Extrakte statt direkt über das Warehouse lesen. Wenn solche Abzweigungen nicht mit erfasst werden, entsteht schnell ein hübscher, aber unvollständiger Graph.
Technisch gesehen greift lineage auf Metadaten zurück: Tabellenstrukturen, Abfragen, Job-Logs, Orchestrierungsdaten, Schemas und manchmal auch Berechtigungsinformationen. Offene Standards wie OpenLineage helfen dabei, solche Metadaten plattformübergreifend zu sammeln, statt sie in jedem Tool separat nachzubauen. Der praktische Nutzen ist simpel: Je weniger Insellösungen, desto eher bleibt die Sicht auf den Datenpfad konsistent. Wenn man diesen Aufbau verstanden hat, wird auch klar, warum die Methode in Analyse und Datenbanken so viel Vertrauen schafft.
Warum Transparenz bei Reports und Datenbanken so viel ausmacht
Ich halte Herkunftsverfolgung vor allem deshalb für wichtig, weil sie drei sehr unterschiedliche Probleme zugleich löst: Verständnis, Verantwortung und Geschwindigkeit. Wer eine Kennzahl erklären muss, braucht eine belastbare Kette vom Rohwert bis zum Dashboard. Wer einen Fehler behebt, braucht die Stelle, an der die Abweichung entstanden ist. Und wer Systeme umbaut, braucht die Informationen über Abhängigkeiten, bevor etwas Produktives kaputtgeht.
| Anwendungsfall | Was die Herkunftsverfolgung liefert | Praktischer Effekt |
|---|---|---|
| Fehlersuche | Pfad vom Report zur Quelle inklusive Transformationen | Schnellere Root-Cause-Analyse und weniger Rätselraten |
| Impact Analysis | Abhängigkeiten zwischen Tabellen, Jobs und Reports | Änderungen lassen sich vor dem Rollout besser bewerten |
| Datenqualität | Wo Werte bereinigt, gefiltert oder aggregiert werden | Fehlerhafte Regeln werden früher sichtbar |
| Migration und Modernisierung | Welche Objekte auf alte Quellen oder Prozesse zeigen | Weniger Risiko bei Umzügen auf neue Plattformen |
| Compliance und Audit | Nachweis, wie Daten verarbeitet und weitergegeben wurden | Mehr Nachvollziehbarkeit in regulierten Umgebungen |
Gerade in Deutschland ist das relevant, wenn personenbezogene Daten, Berichtswege oder Freigabeprozesse sauber dokumentiert sein müssen. Ich würde das nicht nur als Governance-Thema sehen, sondern als Produktivitätshebel: Teams verschwenden schlicht weniger Zeit mit der Suche nach dem Ursprung eines Problems. Von hier ist der Schritt zur Frage naheliegend, wie man solche Metadaten überhaupt sinnvoll einsammelt.
Welche Methoden und Werkzeuge sich 2026 bewähren
In realen Projekten sehe ich drei Ansätze: manuell, automatisiert und hybrid. Manuell bedeutet gepflegte Dokumentation in Katalogen oder Diagrammen. Automatisiert heißt, dass Scanner, Orchestrierer, SQL-Parser oder Plattformfunktionen die Beziehungen selbst ableiten. Hybrid ist meist die brauchbarste Variante, weil sie Automatik für Standardpfade und manuelle Ergänzungen für Sonderfälle kombiniert.
| Ansatz | Stärken | Schwächen | Geeignet für |
|---|---|---|---|
| Manuell | Sehr präzise, leicht erklärbar | Aufwendig, veraltet schnell | Kleine Umgebungen, einzelne Kernprozesse |
| Automatisiert | Skaliert gut, weniger Pflegeaufwand | Erfasst Sonderfälle nicht immer korrekt | Große Datenplattformen, viele Pipelines |
| Hybrid | Guter Kompromiss aus Breite und Kontrolle | Braucht klare Verantwortlichkeiten | Die meisten produktiven Analyse- und DWH-Landschaften |
Wichtig ist weniger das Label des Tools als seine Anschlussfähigkeit. Plattformen wie Microsoft Purview, Apache Atlas, Databricks Unity Catalog oder offene Standards wie OpenLineage sind interessant, wenn sie Metadaten aus Datenbanken, ETL/ELT-Strecken, Notebooks und BI-Werkzeugen zusammenführen können. Ich würde immer prüfen, ob das Tool tabellen- und spaltenbezogene Beziehungen, Run-Informationen und manuelle Ergänzungen sauber zusammenbringt. Sonst bleibt die hübsche Oberfläche am Ende nur eine halbe Wahrheit. Genau an dieser Stelle kippen viele Projekte, wenn sie die typischen Fehler unterschätzen.
Wo die meisten Projekte scheitern
Die größten Probleme entstehen selten durch die Technik allein, sondern durch unklare Erwartungen. Die häufigsten Fehler sehe ich immer wieder:
- Zu grobe Granularität - Tabellenebene reicht nicht, wenn fachliche Kennzahlen aus mehreren Spalten und Regeln entstehen.
- Unvollständige Abdeckung - SQL-Skripte, lokale Exporte, Ad-hoc-Analysen oder BI-Extrakte fehlen im Graphen.
- Veraltete Metadaten - Nach dem nächsten Release stimmt die Dokumentation nicht mehr mit der Realität überein.
- Keine Verantwortlichkeiten - Wenn niemand für Pflege und Review zuständig ist, verliert das System schnell Vertrauen.
- Zu viel Vertrauen in Automatik - Scanner erkennen vieles, aber nicht jede bedingte Logik, jeden UDF-Call und nicht jeden Sonderpfad.
Eine technische Grenze ist besonders wichtig: Nicht jede Plattform liefert automatisch lineare, lückenlose Nachweise bis auf Zeilen- oder Einzelwert-Ebene. In der Praxis endet die Nachverfolgung oft auf Job-, Tabellen- oder Spaltenebene. Das ist nicht schlecht, aber man muss wissen, wo die Grenze liegt, damit man aus dem Graphen keine falschen Sicherheitsversprechen ableitet. Wenn diese Grenzen klar sind, lässt sich der Einsatz viel realistischer planen.
Worauf ich vor dem produktiven Einsatz achte
Bevor ich so ein System in den Alltag entlasse, kläre ich immer dieselben Fragen: Welche Pipelines sind geschäftskritisch? Welche Ebene ist wirklich nötig? Wer prüft die Metadaten regelmäßig? Und wie schnell muss der Herkunftsnachweis nach einem Change aktualisiert sein? Ohne diese Antworten wird aus Governance schnell nur ein weiteres Dashboard.
- Mit einem geschäftskritischen Datenpfad starten, nicht mit der ganzen Plattform.
- Die nötige Granularität festlegen: Tabelle, Spalte oder beides.
- Eigentümer pro Domäne benennen, damit Pflege nicht liegen bleibt.
- Quellen definieren, die als Wahrheit gelten, zum Beispiel Orchestrator, Warehouse und BI-System.
- Ad-hoc-Pfade und Sonderfälle bewusst dokumentieren, statt sie stillschweigend zu ignorieren.
- Die Aktualisierung an den Release- und Deployment-Zyklus koppeln, damit Herkunftsinformationen nicht veralten.
Wenn ich das auf einen Satz verdichten müsste, dann so: Gute Datenherkunft ist kein einmaliges Dokument, sondern ein fortlaufender Abgleich zwischen Systemen, Prozessen und Verantwortung. Wer klein anfängt, die wichtigsten Pfade sauber erfasst und die Pflege als Teil des Betriebs behandelt, bekommt ein Werkzeug, das Fehler schneller sichtbar macht und Änderungen deutlich sicherer. Genau dort liegt der eigentliche Wert - nicht im Diagramm, sondern in den Entscheidungen, die danach besser werden.