
Die wichtigsten Punkte auf einen Blick
- Heute meint der Begriff meist entweder Azure Synapse Analytics mit Dedicated SQL Pool oder Microsoft Fabric Data Warehouse.
- Für neue Vorhaben verweist Microsoft inzwischen klar stärker auf Fabric, während Synapse für bestehende MPP-Workloads wichtig bleibt.
- Die Performance hängt stark von Verteilung, Statistikpflege und einem sauberen Datenmodell ab.
- Geeignet ist die Lösung vor allem für große, leselastige Analyse- und BI-Szenarien.
- Für kleine, transaktionale oder stark unstrukturierte Workloads ist sie meist die falsche Wahl.
Was hinter dem Begriff heute wirklich steckt
Der Ausdruck wird im Alltag etwas locker verwendet. Gemeint ist meistens die Microsoft-Welt für analytische Datenhaltung in der Cloud, also entweder der Dedicated SQL Pool in Azure Synapse Analytics oder das neuere Fabric Data Warehouse. Historisch stammt viel der Terminologie aus dem früheren Azure SQL Data Warehouse, deshalb taucht der alte Sprachgebrauch in Suche, Dokumentation und Teams noch immer auf.
Wichtig ist die Unterscheidung zwischen einem Warehouse und einer reinen Abfrageschicht. Ein Warehouse hält strukturierte Daten so vor, dass sie schnell aggregiert, gefiltert und in BI-Tools weiterverarbeitet werden können. Ein Serverless-SQL-Ansatz ist dagegen eher ein Werkzeug, um Daten im Lake direkt abzufragen. Das ist nützlich, ersetzt aber nicht automatisch ein echtes analytisches Kernsystem.
Microsoft verschiebt die Perspektive inzwischen deutlich in Richtung Fabric. Für neue Datenplattformen ist das kein kosmetischer Unterschied, sondern eine echte Architekturentscheidung: entweder ein spezialisierter Analysedienst mit klarer Trennung von Compute und Storage oder eine breiter integrierte SaaS-Plattform mit Warehouse, Lakehouse, Data Engineering und Reporting unter einem Dach. Genau daraus ergeben sich die nächsten Fragen zur Technik und zum Betrieb.
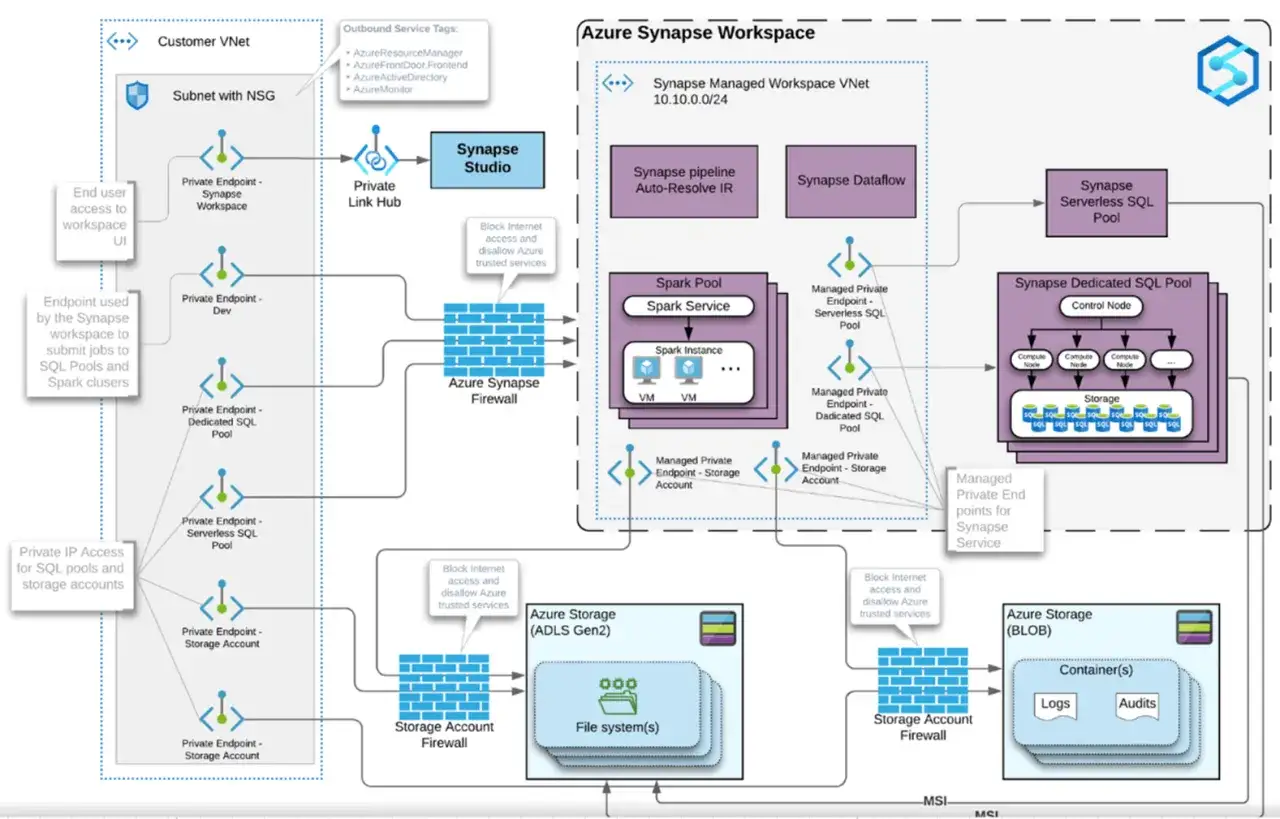
Wie die MPP-Architektur die Analyse beschleunigt
Der technische Kern von Synapse ist die MPP-Architektur, also Massively Parallel Processing. Abfragen werden nicht auf einer einzigen Maschine abgearbeitet, sondern auf mehrere Compute-Knoten verteilt. Ein Control Node koordiniert die Anfrage, die Compute Nodes erledigen die eigentliche Arbeit parallel, und der Data Movement Service verschiebt Daten nur dann zwischen den Knoten, wenn es für ein korrektes Ergebnis nötig ist.
Für die Praxis bedeutet das vor allem drei Dinge: Erstens lässt sich Compute unabhängig von Storage skalieren. Zweitens kann ein dedizierter Pool pausiert werden, während die Daten erhalten bleiben. Drittens laufen große Aggregationen und Joins deutlich stabiler, wenn die Verteilung sauber gewählt ist. Microsoft beschreibt die Ausführung intern mit 60 Distributionen; jede Abfrage wird also in viele kleine Teilaufgaben zerlegt.
Besonders wichtig ist die Wahl der Tabellenverteilung. Ich würde sie nie als Nebensache behandeln, weil sie über Geschwindigkeit oder Frust entscheidet.
| Verteilungsart | Wofür sie gut ist | Worauf man achten sollte |
|---|---|---|
| Hash | Große Faktentabellen mit vielen Joins und Aggregationen | Der Schlüssel muss gut gewählt sein, sonst entsteht Daten-Skew |
| Round-robin | Staging-Tabellen und schnelle Ladeprozesse | Für komplexe Joins oft nur zweite Wahl, weil Daten neu verteilt werden müssen |
| Replicated | Kleine Dimensionstabellen mit häufigen Joins | Zusätzlicher Speicher und mehr Aufwand beim Schreiben |
Dazu kommt die spaltenorientierte Speicherung. Sie ist für analytische Abfragen deutlich geeigneter als klassische zeilenorientierte Speicherung, weil viele Auswertungen nur auf wenigen Spalten, aber auf sehr vielen Zeilen arbeiten. Genau hier liegt der Grund, warum solche Systeme bei Reporting und BI oft ein Vielfaches schneller wirken als transaktionale Datenbanken. Aus dieser Architektur folgt allerdings auch ziemlich klar, wann die Lösung stark ist und wann nicht.
Wann die Lösung stark ist und wann sie bremst
Ich sehe den größten Nutzen immer dann, wenn viele Daten aus unterschiedlichen Quellen in einem stabilen analytischen Modell zusammenlaufen. Typische Anwendungsfälle sind Unternehmensberichte, Finanzanalysen, Produktkennzahlen, historische Zeitreihen, Vertriebscontrolling oder zentrale Metrik-Layer für Power BI. Wenn Abfragen regelmäßig wiederkehren und große Datenmengen konsistent ausgewertet werden sollen, ist das genau das richtige Terrain.
Weniger passend ist die Plattform für operative Systeme mit vielen kleinen Schreibvorgängen, kurzen Transaktionen und stark wechselnden Datenstrukturen. Ein Warehouse ist kein Ersatz für eine OLTP-Datenbank. Es ist auch keine gute Idee, es als Sammelbecken für alles zu missbrauchen, was irgendwo im Unternehmen anfällt. Wer Daten unstrukturiert hineinkippt, bekommt am Ende eher eine teure Ablage als eine belastbare Analysegrundlage.
- Gut geeignet für star schemas, Faktentabellen, Management-Reporting und wiederkehrende SQL-Auswertungen.
- Eher ungeeignet für operative Applikationen, hohe Schreibfrequenz und sehr kleine Datensätze.
- Besonders stark bei stabilen Ladefenstern, sauberem Datenmodell und klaren Abfragepfaden.
Genau an dieser Stelle stellt sich die praktische Frage, welche Microsoft-Variante man heute überhaupt wählen sollte. Für neue Projekte ist das die wichtigste Entscheidung im ganzen Themenfeld.
Synapse oder Fabric für neue Projekte
Für bestehende Installationen ist Synapse mit Dedicated SQL Pool weiterhin relevant, vor allem wenn ein etabliertes MPP-Setup, feste ETL-Strecken und eingespielte Betriebsprozesse vorhanden sind. Für neue Vorhaben fällt meine Bewertung inzwischen oft zugunsten von Fabric aus, weil Microsoft dort die analytischen Bausteine stärker zusammenzieht und weniger Einzelbetrieb verlangt.
Der Unterschied ist nicht nur ein Namenswechsel, sondern ein anderes Betriebsmodell. Fabric ist eine SaaS-Plattform mit OneLake als gemeinsamem Datenfundament; das Warehouse dort arbeitet auf Delta-basierten Tabellen und ist enger mit Data Engineering und Power BI verzahnt. Synapse bleibt dagegen das klassischere MPP-System mit DWU-basierter Skalierung, klarer Trennung von Compute und Storage und der Option, Compute zu pausieren.
| Kriterium | Synapse Dedicated SQL Pool | Fabric Data Warehouse |
|---|---|---|
| Zielbild | Bewährtes MPP-Warehouse für analytische Großlasten | Integrierte Warehouse-Lösung in einer breiteren Analytics-Plattform |
| Betriebsaufwand | Mehr Tuning und bewusste Kapazitätssteuerung | Weniger Einzelservice-Management, stärker als SaaS gedacht |
| Datenmodell | Relationale Tabellen mit starker Ausrichtung auf analytische SQL-Workloads | Warehouse-Items auf Delta-Grundlage mit T-SQL und ACID-Fähigkeiten |
| Integration | Gut für bestehende Azure- und Synapse-Landschaften | Sehr eng mit Power BI, Data Engineering und dem Fabric-Ökosystem verzahnt |
| Mein Praxisurteil | Sinnvoll bei stabilen Alt- oder Lift-and-shift-Szenarien | Oft die bessere Wahl für neue Analyseplattformen |
Ich würde die Entscheidung nicht ideologisch treffen. Wenn ein Synapse-Setup sauber läuft, gute Kosten liefert und die Teams es beherrschen, ist ein Wechsel nicht automatisch sinnvoll. Wenn ein Projekt aber neu startet, mehrere Analyse-Teams zusammenführen soll und möglichst wenig Infrastrukturpflege verträgt, spricht heute viel für Fabric. Sobald die Plattform feststeht, entscheidet das Datenmodell über den Rest.
So setze ich ein Warehouse in der Praxis auf
In der Umsetzung fange ich nie mit der Technologie an, sondern mit der Frage, welche Kennzahlen wirklich gebraucht werden. Erst wenn klar ist, welche Berichte, Dashboards und Ad-hoc-Abfragen zuverlässig funktionieren müssen, lohnt sich das Feintuning. Sonst optimiert man am falschen Ende.
- Datenmodell auf den Analysezweck zuschneiden. Ich arbeite bevorzugt mit klaren Fakt- und Dimensionstabellen, damit Abfragen einfach bleiben und Joins nicht ausufern.
- Ladeweg festlegen. Für Batch-Lasten eignen sich Pipelines, Copy-orientierte Ladepfade oder vorbereitete Staging-Tabellen. Der Punkt ist nicht das Tool, sondern die Wiederholbarkeit.
- Verteilung bewusst wählen. Große Faktentabellen profitieren meist von Hash-Verteilung, kleine Referenztabellen oft von Replikation. Staging kann round-robin bleiben.
- Security früh einbauen. Rollen, Entra-ID-Authentifizierung, Row-Level Security, Column-Level Security und Verschlüsselung gehören in das Design, nicht in die Nachrüstung.
- Mit realen Queries testen. Ich prüfe nicht nur Ladezeiten, sondern die zehn oder zwölf Abfragen, die im Alltag wirklich zählen.
- Statistiken und Monitoring pflegen. Ohne aktuelle Statistiken verliert ein analytisches System schnell an Präzision bei der Optimierung.
Für Deutschland kommt noch ein Punkt dazu, den viele Teams zu spät ernst nehmen: Region, Mandantengrenzen und Protokollierung sollten früh feststehen. Gerade bei personenbezogenen oder geschäftskritischen Daten ist es deutlich angenehmer, Governance am Anfang sauber zu ziehen, als später unter Betriebsdruck nachzubessern. Damit sind die typischen Planungsfehler schon fast vorgezeichnet.
Typische Fehler, die ich in Analyseprojekten immer wieder sehe
Der häufigste Fehler ist erstaunlich banal: Das Warehouse wird wie eine normale Anwendungsdatenbank behandelt. Dann werden zu viele kleine Writes erzeugt, das Modell wird zu fein granuliert und die Performance leidet, obwohl die Plattform an sich stark genug wäre. Ein Warehouse braucht analytische Disziplin, keine operative Hektik.
Ein zweiter Klassiker ist die falsche Verteilung. Daten-Skew bedeutet, dass einzelne Distributionen viel mehr Last tragen als andere. Dann wartet die Gesamtabfrage auf den langsamsten Teil, und das System verliert einen großen Teil seines Parallelvorteils. Das Problem sieht man oft erst unter echter Last, deshalb sollte man es vor dem Go-live bewusst provozieren.
Ebenso unterschätzt werden Pflegeaufgaben wie Statistiken, neue Dateigrößen beim Laden und saubere Zugriffsmodelle. Wer diese Grundlagen ignoriert, erkauft sich ein paar Wochen Tempo und zahlt danach dauerhaft mit schlechteren Plänen, unnötigen Kosten oder unklaren Berechtigungen. Ich halte das für den Bereich, in dem sich professionelle Warehouses von hübschen Demo-Setups unterscheiden.
- Keine klare Trennung zwischen operativen und analytischen Workloads.
- Falsch gewählte Distributionsschlüssel bei großen Tabellen.
- Zu viele kleine Dateien oder ungeplante Mini-Batches beim Laden.
- Statistiken werden nicht aktualisiert, obwohl sich das Datenvolumen verschiebt.
- Governance, Audit und Rechtekonzept werden erst nach dem ersten Produktivproblem diskutiert.
Wenn man diese Fehler vermeidet, ist die Plattform nicht nur technisch sauber, sondern auch im Alltag deutlich ruhiger zu betreiben. Genau deshalb würde ich neue Projekte heute eher nüchtern als spektakulär angehen.
Womit ich heute für neue Analyseplattformen starten würde
Für neue Vorhaben würde ich zuerst prüfen, ob Microsoft Fabric Data Warehouse die bessere Grundlage bietet. Die Kombination aus zentralem Datenfundament, integrierten Analysewerkzeugen und geringerem Betriebsaufwand ist für viele Teams schlicht praktischer als ein separat gepflegtes Klassik-Warehouse. Wenn die Organisation bereits stark auf Synapse aufgesetzt ist, bleibt das aber eine valide und oft wirtschaftliche Lösung.
Mein pragmatischer Startpunkt ist immer derselbe: Analyseziele festziehen, das Modell auf wenige belastbare Fakten zuschneiden, Verteilung und Security bewusst designen und erst dann über Skalierung sprechen. Genau in dieser Reihenfolge entsteht ein Warehouse, das nicht nur Daten speichert, sondern echte Entscheidungen beschleunigt. Die Technik ist dabei wichtig, aber die Architekturdisziplin ist wichtiger.