
Ein moderner Daten-Stack entscheidet heute oft darüber, ob Analysen nach Minuten oder erst nach Tagen verfügbar sind. Er verbindet operative Datenbanken, Cloud-Speicher, Transformationslogik und BI so, dass aus Rohdaten verlässliche Kennzahlen werden. Der Begriff modern data stack beschreibt genau dieses Zusammenspiel: nicht ein einzelnes Produkt, sondern eine Architektur, die Daten in der Cloud schneller nutzbar macht. Gerade für Unternehmen in Deutschland ist das relevant, weil Datenquellen meist heterogen sind und Governance, DSGVO sowie Datenqualität nicht erst am Ende mitgedacht werden dürfen.
Die wichtigsten Punkte auf einen Blick
- Der Ansatz besteht aus mehreren Schichten: Datenaufnahme, Speicher, Transformation, Orchestrierung, Semantik und BI.
- Operative Datenbanken bleiben wichtig, ersetzen aber keine Analyseschicht für Reporting und Self-Service-Analytics.
- Für viele Teams ist ein schlanker Aufbau mit 4 bis 6 Kernbausteinen sinnvoller als eine überladene Toollandschaft.
- In Deutschland zählen Datenschutz, Datenresidenz und klare Zugriffsrechte besonders stark.
- 2026 prägen Lakehouse-Architekturen, semantische Schichten und KI-gestützte Workflows die Entwicklung.
Was hinter dem modernen Daten-Stack steckt
Ich sehe diesen Ansatz als Baukasten für Analyse und nicht als Ersatz für eine einzelne Datenbank. Operative Systeme erledigen Transaktionen schnell und sauber; die analytische Schicht sammelt, ordnet und modelliert Daten so, dass Fachbereiche damit arbeiten können. Der wichtigste Architekturwechsel ist oft ETL zu ELT: Erst werden Daten geladen, dann im Zielsystem bereinigt und modelliert.
| Baustein | Aufgabe | Warum er wichtig ist |
|---|---|---|
| Datenaufnahme | Quellen wie Datenbanken, APIs und Dateien anbinden | Verhindert manuelle Exporte und Medienbrüche |
| Speicher | Rohdaten zentral ablegen | Schafft Historie, Skalierung und eine gemeinsame Grundlage |
| Transformation | Daten bereinigen, anreichern und modellieren | Macht aus Rohdaten belastbare Kennzahlen |
| Orchestrierung | Jobs zeitlich und logisch steuern | Sichert reproduzierbare Läufe und Abhängigkeiten |
| Semantische Schicht | Geschäftsbegriffe und Metriken vereinheitlichen | Reduziert widersprüchliche KPI-Definitionen |
| BI und Self-Service | Analysen, Dashboards und Ad-hoc-Fragen bedienen | Bringt Erkenntnisse in die Fachbereiche |
Wichtig ist die Trennung der Rollen: Eine operative Datenbank beantwortet andere Fragen als ein Warehouse oder ein Lakehouse. Wer diese Schichten vermischt, bekommt oft zwar Daten, aber keine verlässliche Analyse. Genau deshalb lohnt sich im nächsten Schritt der Blick auf die Architektur in der Praxis.
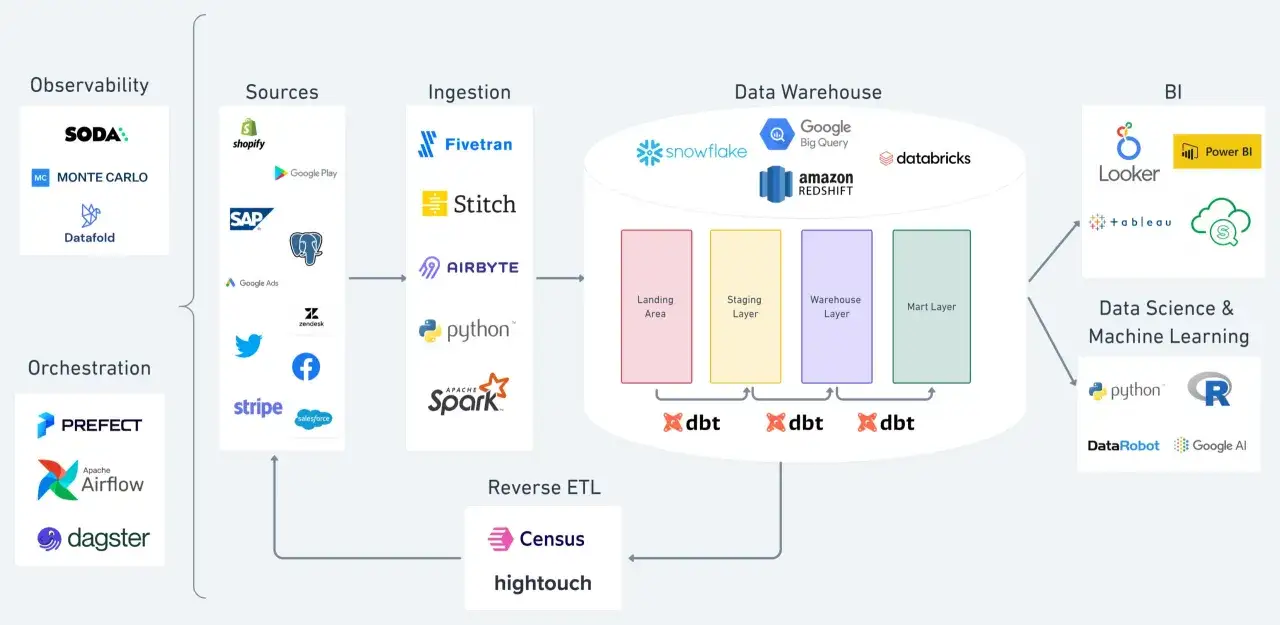
Wie die Architektur in der Praxis zusammenwirkt
Ein typischer Datenfluss beginnt in einer operativen Datenbank wie PostgreSQL, MySQL oder einem ERP-System. Über Batch-Jobs oder Streaming landet er in einer zentralen Analyseplattform; dort werden Rohdaten bereinigt, mit Geschäftslogik angereichert und in Kennzahlen übersetzt. Erst danach kommen Dashboards, Ad-hoc-SQL oder ML-Workloads ins Spiel.
| Systemtyp | Stärke | Grenze | Typische Rolle |
|---|---|---|---|
| Operative Datenbank | Schnelle Transaktionen und saubere Schreibvorgänge | Schwere Analysen bremsen das System | Quelle der Wahrheit für Bestellungen, Kunden oder Buchungen |
| Data Warehouse | Starke SQL-Analysen, Governance und klare Struktur | Benötigt Modellierung und saubere Ladeprozesse | Reporting, Controlling und Self-Service-Analytics |
| Lakehouse | Strukturierte und semi-strukturierte Daten zusammenführen | Mehr Disziplin bei Governance und Zugriffen nötig | Breite Analyse-, Streaming- und KI-Szenarien |
Ein Beispiel aus dem Alltag: Bestellungen werden in der operativen Datenbank gespeichert, Webevents kommen aus dem Tracking, Rechnungsdaten aus dem Finance-System. Wenn diese Quellen nicht auf dieselbe Definition von Kunde, Umsatz und Storno treffen, sieht jedes Team eine andere Wahrheit. Genau deshalb sind Modellierung und Semantik keine Nebensache, sondern der Kern der Architektur.
Sobald dieser Datenfluss klar ist, wird auch verständlich, warum manche Unternehmen eher zum Warehouse und andere eher zum Lakehouse tendieren. Die Entscheidung folgt nicht einem Trend, sondern dem gewünschten Zusammenspiel aus Struktur, Flexibilität und Betriebsaufwand.
Welche Bausteine sich heute bewährt haben
Für die Praxis denke ich nicht in Produktlisten, sondern in Funktionsblöcken. Trotzdem hilft es, einige typische Werkzeuge einzuordnen: Anbindung mit Fivetran oder Airbyte, zentrale Speicherung in Snowflake, BigQuery oder Databricks, Modellierung mit dbt, Steuerung mit Airflow oder Dagster und Auswertung in Power BI, Tableau oder Looker. Entscheidend ist nicht, alles zu haben, sondern die Rollen sauber zu trennen.
| Kategorie | Wofür sie gut ist | Worauf ich achte |
|---|---|---|
| Ingestion | Quellen zuverlässig anbinden | Connector-Abdeckung, Fehlerbehandlung, Kosten pro Quelle |
| Storage und Compute | Daten speichern und abfragen | Skalierung, Preismodell, Datenresidenz |
| Transformation | Logik versioniert im Code abbilden | Tests, Git-Workflows, Verständlichkeit der Modelle |
| Orchestration | Abhängigkeiten und Läufe steuern | Monitoring, Wiederanläufe, Transparenz |
| Semantische Schicht | Kennzahlen und Dimensionen vereinheitlichen | Freigaben, Definitionen, Fachsprache |
| BI und Observability | Ergebnisse sichtbar machen und Fehler erkennen | Self-Service, Alerting, Zugriffsrechte |
Ich würde bei der Auswahl immer drei Fragen stellen: Muss das Team die Infrastruktur selbst betreiben? Brauchen wir Minuten- oder Tagesaktualität? Und wie stark begrenzen Datenschutz und Audit-Anforderungen die Cloud-Nutzung? Erst wenn diese Antworten klar sind, wird aus einem Toolkatalog eine belastbare Architektur. Damit landet man direkt bei der Frage, wann sich der Aufwand überhaupt lohnt.
Warum sich Unternehmen dafür entscheiden und wo die Grenzen liegen
Der Hauptvorteil ist nicht nur Geschwindigkeit, sondern Kontrolle: Daten kommen planbarer an, Modelle werden versionierbar, und Fachbereiche bekommen eine gemeinsame Sicht auf Kennzahlen. Das wirkt besonders dort stark, wo viele Teams dieselben Daten nutzen und niemand mehr Excel-Exporte per Mail pflegen will. Ein schlankes Setup mit 4 bis 6 Kernbausteinen ist für viele Teams realistischer als eine ausufernde Toollandschaft.
- Mehr Tempo: Neue Quellen lassen sich meist schneller anbinden als in monolithischen Altarchitekturen.
- Mehr Transparenz: Versionierte Modelle und Tests machen Datenflüsse nachvollziehbar.
- Mehr Skalierung: Speicher und Compute wachsen in der Cloud oft besser mit als lokale Systeme.
- Mehr Fachlichkeit: Eine semantische Schicht reduziert widersprüchliche Kennzahlen.
- Mehr Betriebsaufwand: Jede zusätzliche Komponente braucht Monitoring, Pflege und Zuständigkeit.
Die Grenzen liegen meist an den Schnittstellen: Jede zusätzliche Quelle erhöht Komplexität, jede doppelte Transformation kostet Zeit, und jede unklare KPI-Definition erzeugt Misstrauen. In regulierten Umgebungen kommt hinzu, dass Rollenmodelle, Protokollierung und Löschkonzepte nicht erst nach dem Go-live geklärt werden sollten. Ich würde hier lieber einmal zu streng als einmal zu locker planen, weil Nacharbeiten später teuer werden.
Wer das sauber aufsetzt, kann danach gezielt entscheiden, wie der Einstieg aussehen sollte und wo Legacy-Systeme zunächst weiterlaufen dürfen.
Wie ich den Einstieg für ein Team planen würde
Ich würde nie mit dem Dashboard beginnen, sondern mit dem Datenmodell und den Fragen, die beantwortet werden sollen. Ein sauberer Einstieg verhindert, dass man später Modelle umbaut, nur weil die erste Version zu nah an den Rohquellen gebaut wurde. Besonders bei bestehenden Datenbanken lohnt sich ein gestufter Ansatz statt eines radikalen Schnitts.
- Use Case festlegen: Zwei bis drei Fragen definieren, die das Setup wirklich beantworten soll, etwa Umsatz, Churn oder Kampagnenwirkung.
- Quellen inventarisieren: Alle relevanten Datenbanken, APIs, Dateien und Event-Streams dokumentieren.
- Zentrale Analyseplattform wählen: Ein Warehouse oder Lakehouse festlegen, bevor parallele Analyseinseln entstehen.
- Kernmetriken modellieren: Die wichtigsten Kennzahlen zuerst bauen, nicht alle Randfälle gleichzeitig.
- Betrieb absichern: Tests, Monitoring, Zugriffsrechte und Data Contracts ergänzen. Ein Data Contract ist die Vereinbarung darüber, welches Schema, welche Aktualität und welche Verantwortung für eine Datenquelle gelten.
Wenn bereits ein Legacy-Warehouse existiert, funktioniert Parallelbetrieb oft besser als eine Big-Bang-Migration. So lassen sich Ergebnisse vergleichen, Risiken begrenzen und Fachbereiche schrittweise mitnehmen. Genau an dieser Stelle trennt sich ein sauberes Architekturprojekt von einem bloßen Toolwechsel.
Was 2026 bei Datenplattformen wirklich zählt
2026 sehe ich drei Entwicklungen, die tatsächlich Substanz haben: Erstens konvergieren Warehouse- und Lakehouse-Ansätze immer stärker. Zweitens wird die semantische Schicht wichtiger, weil KI-gestützte Analyse nur mit sauberen Definitionen verlässlich bleibt. Drittens wird Observability vom Nice-to-have zum Pflichtbaustein, weil niemand Datenpipelines nur auf Hoffnung betreiben sollte.
- Lakehouse- und Warehouse-Modelle werden stärker zusammen gedacht statt strikt gegeneinander gestellt.
- Semantische Schichten sichern einheitliche Begriffe für Umsatz, Kunde, Aktivität und Bestand.
- KI-gestützte Assistenz hilft beim Modellieren und Abfragen, ersetzt aber keine Governance.
- Data Observability verkürzt die Zeit bis zur Erkennung fehlerhafter Läufe oder Schemaänderungen.
Für die meisten Organisationen ist deshalb nicht der größte, sondern der klarste Stack die beste Wahl. Wenn Architektur, Datenbanken, Governance und Analyse auf denselben Zielen aufbauen, wird aus einem Sammelsurium von Tools eine belastbare Datenplattform, die auch in zwei Jahren noch verständlich und wirtschaftlich bleibt.